The below is my pandas dataframe, each column contains either 0 or 1. I am trying to replace the existing 'toxic' with 1 if at least one of the other columns (severe_toxic, ..., identity hate) contains 1.
I tried the below code but it gives error.
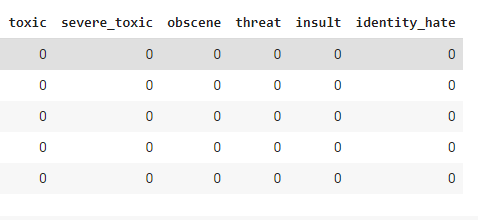
Code I tried:
# a1 - above dataframe's name
a1['toxic'] = [1 if any(a1[[severe_toxic','obscene','threat','insult','identity_hate']]) ==1]
CodePudding user response:
Use:
df['toxic'] = np.where((df[df.columns[1:]]==1).any(axis=1), 1, df['toxic'])
Input:
toxic severe_toxic obscene threat insult identity_hate
0 0 0 0 0 0 0
1 0 0 0 0 0 0
2 0 0 0 0 0 1
3 0 0 0 0 0 1
4 0 0 0 0 0 0
Output:
toxic severe_toxic obscene threat insult identity_hate
0 0 0 0 0 0 0
1 0 0 0 0 0 0
2 1 0 0 0 0 1
3 1 0 0 0 0 1
4 0 0 0 0 0 0
Setup:
df = pd.DataFrame(data={'toxic':[0]*5,
'severe_toxic':[0]*5,
'obscene':[0]*5,
'threat':[0]*5,
'insult':[0]*5,
'identity_hate':[0,0,1,1,0]})
CodePudding user response:
Use any from Pandas and not from Python:
cols = ['severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
a1['toxic'] = a1[cols].any(axis=1).astype(int)