I imported a csv-file to a pandas dataset (phyton)
| ParamID | EquipmentID | SetValue | |
|---|---|---|---|
| 0 | 1 | Line1 | 217.0 |
| 1 | 2 | Line1 | 3.0 |
| 2 | 4 | Line1 | 0.0 |
| 3 | 6 | Line1 | 17.0 |
| 4 | 2 | Line2 | 3.0 |
| 5 | 4 | Line2 | 0.0 |
| 6 | 6 | Line2 | 17.0 |
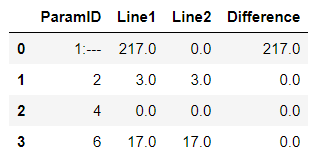
i would like to change this to another table where i can see the difference/Line
| ParamID | LINE1 | LINE2 | Difference | |
|---|---|---|---|---|
| 0 | 1:--- | 217.0 | / | 217.0 |
| 1 | 2 | 3.0 | 3.0 | 0 |
| 2 | 4 | 0.0 | 0.0 | 0 |
| 3 | 6 | 17.0 | 17.0 | 0 |
I tried pivot1=pd.pivot_table(new_df, index = 'Region') but this gives an error: "KeyError: 'Region'"
Additional question on the given solution:
If "Line1" and "Line2" where numbers (21 and 22 )in the first table why doesdf1['Difference'] = (df1['21'].replace(np.nan,0) - df1['22'].replace(np.nan,0))gives a KeyError on 21
CodePudding user response:
You can use 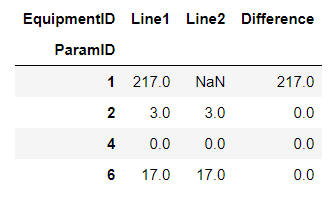
Update with full answer (touch up the table):
df1 = df.pivot('ParamID','EquipmentID','SetValue').reset_index()
df1['Difference'] = (df1['Line1'].replace(np.nan,0) - df1['Line2'].replace(np.nan,0))
df1['ParamID'] = np.where((np.isnan(df1.Line1)) | (np.isnan(df1.Line2)), df1['ParamID'].astype(str) ':---' , df1['ParamID'])
df1.replace(np.nan,0,inplace=True)
df1.columns.name=''