I have a pandas DF with a column containing strings.
(I take the example from 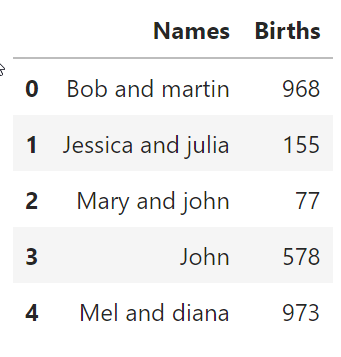
Giving a string like "martin andrew bob", I would like to filter the DF to get the subDF with the rows containing in the name all the words (in any order and case) of the string.
What is the best way to go? My solution would involve a for loop adding the masks as lists of booleans but this solution seems to me to cumbersome.
CodePudding user response:
This is my suggestion:
my_str = 'martin andrew bob'
a[a['Names'].str.lower()
.str.split()
.apply(set(my_str.lower().split()).issubset)
].reset_index(drop=True)
Output:
Names Births
0 Bob and martin and Andrew 968
1 martin bob diana and Andrew 968
I'm adding lower() function to my_str, but if you're sure that string is always given in lowercase you can skip it.