apply pandas groupby or pivot function apply aggregate sum & count for two categorical columns based on another categorical column
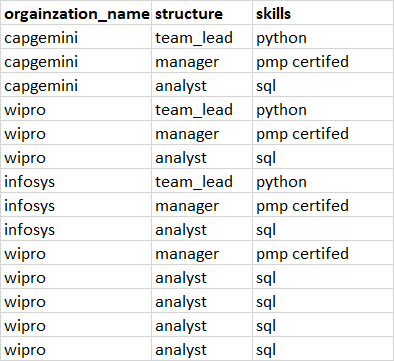
output I need
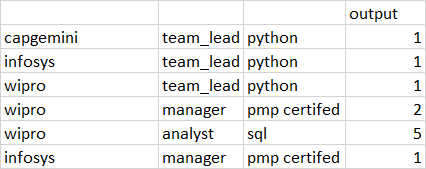
orgainzation_name structure skills
capgemini team_lead python
capgemini manager pmp_certified
capgemini analyst SQL
wipro team_lead python
wipro manager pmp_certified
wipro analyst SQL
infosys team_lead python
infosys manager pmp certifed
infosys analyst SQL
wipro manager pmp_certifed
wipro analyst SQL
wipro analyst SQL
wipro analyst SQL
wipro analyst SQL
capgemini team_lead python
CodePudding user response:
(
df.value_counts(['orgainzation_name','structure','skills'])
.reset_index()
.sort_values(['orgainzation_name','structure','skills'],ascending=[True,False,True])
)
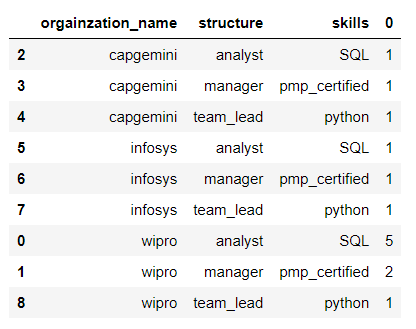
You can control the sort order by manipulating ascending=.