I ran a random classifier on my text data and calculated a confusion matrix using the following code
#Plot the confusion matrix
plot_confusion_matrix(y_test, y_pred, normalize=False,figsize=(15,8))
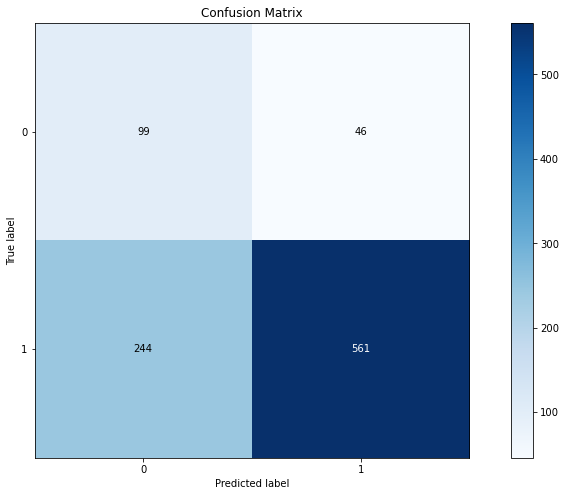
The above fig is what my confusion matrix looks like. Now, I want to see some datasets that belong to false negatives, false positives, true positives and true negative?. So far written following codes:
import pandas as pd
df_test = pd.DataFrame(x_test)
df_test['case'] = np.where((y_test == 1) & (y_pred == 0), 'false negative', np.where((y_test == 0) & (y_pred == 1), 'false positive', 'correct prediction'))
df_test.head(5)
This code gives me false negative, false positive and correct predictions but does not give me true positive and true negative. Any idea how to modify this code so that df_test shows all these label results datasets: false negative, false positive, true positive, true negative and correct predictions? Thanks in advance
CodePudding user response:
You can create a label array, then use numpy indexing index:
labels = np.array(['true negative', # y_test, y_pred = 0,0
'false positive', # y_test, y_pred = 0,1
'false negative', # y_test, y_pred = 1,0
'true positive' # y_test, y_pred = 1,1
])
df_test['case'] = labesl[y_test * 2 y_pred]
CodePudding user response:
You could try using numpy.select here. eg:
condlist = [
(y_test == 1) & (y_pred == 1), # True positive
(y_test == 1) & (y_pred == 0), # False Negative
(y_test == 0) & (y_pred == 0), # True negative
(y_test == 0) & (y_pred == 1), # False positive
]
choicelist = ['true positive', 'false negative', 'true negative', 'false positive']
df_test['case'] = np.select(condlist, choicelist)