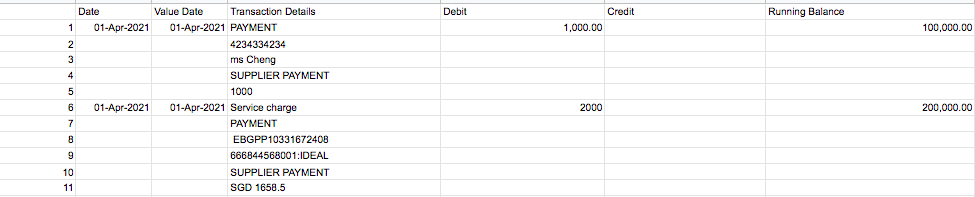
I have the following dataset, where the 'transaction details' column stores all the values for every entry, but in different rows, when it should be storing every entry in the same row. Is there any way this could be done, so that if the first value of 'Transaction Details' is called, all the relevant lines are printed out, instead of just the first line?
Perhaps
CodePudding user response:
With df your dataframe you could do something like this:
import numpy as np
import pandas as pd
df_new = df[~df.Date.isna()].reset_index(drop=True)
df_new["Transaction Details"] = (
df["Transaction Details"]
.groupby(np.where(df.Date.isna(), 0, 1).cumsum())
.apply(lambda col: ", ".join(str(item) for item in col))
.reset_index(drop=True)
)
Just as an illustration: Result - df_new - for the following dataframe
df = pd.DataFrame(
{
"Date": [1, np.NaN, np.NaN, 2, np.NaN, np.NaN, np.NaN],
"Transaction Details": ["a", "b", "c", "d", "e", "f", "g"]
}
)
Date Transaction Details
0 1.0 a
1 NaN b
2 NaN c
3 2.0 d
4 NaN e
5 NaN f
6 NaN g
is
Date Transaction Details
0 1.0 a, b, c
1 2.0 d, e, f, g
If df["Transaction Details"] only contains strings, then you can replace
.apply(lambda col: ", ".join(str(item) for item in col))
with .apply(", ".join).
CodePudding user response:
Setting up
Let's create some sample data first.
df = pd.DataFrame({
"Date": ["01-Apr", np.nan, np.nan, "02-Apr", np.nan],
"Details": ["Payment", "Supplier Payment", "1000", "Payment", "SGD 1658.5"]
})
Date Details
0 01-Apr Payment
1 NaN Supplier Payment
2 NaN 1000
3 02-Apr Payment
4 NaN SGD 1658.5
Merging without separators
If you want to merge the rows without any separators in between, you can try this.
df["Date"] = df["Date"].ffill()
df = df.fillna("").groupby("Date", as_index=False).sum()
Output
This yields the following result.
Date Details
0 01-Apr PaymentSupplier Payment1000
1 02-Apr PaymentSGD 1658.5
Merging with separators
Things will get more complicated if you want to have some separators between the merged values.
sep = ", "
df["Date"] = df["Date"].ffill()
df["Details"] = sep
df = df.fillna("").groupby("Date", as_index=False).sum()
df["Details"] = df["Details"].str[:-1 * len(sep)]
Output
This gives the following result.
Date Details
0 01-Apr Payment, Supplier Payment, 1000
1 02-Apr Payment, SGD 1658.5