I have made the following count table taking the Centers as side break and multiple different columns as top break. I'm unable to understand why a specific value from a column comes at last row in dataframe. Is it some way the data is sorted by the dataframe.Is there a way to stop this default sorting Below is my code:
cols=['Gender','QAge_Post','SEC']
q2=(nb.melt(id_vars='Center_Name',value_vars=cols)
.groupby([pd.Grouper(key='Center_Name'),'variable','value'])
.size()
.unstack(level=[1,2],fill_value=0))
q2.to_excel('Basic.xlsx')
q2.insert(0, 'Total', q2['Gender'].sum(axis=1))
The output is as follows
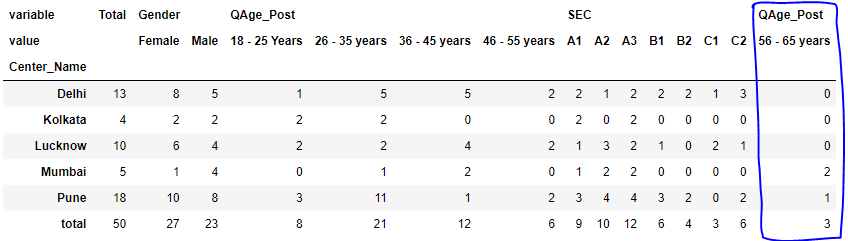
I want column 56-65 years along with the other age parameters, i.e after column 46-55 years. Many thanks
CodePudding user response:
The first idea is sorting MultiIndex.
q2=(nb.melt(id_vars='Center_Name', value_vars=cols)
.groupby([pd.Grouper(key='Center_Name'), 'variable', 'value'])
.size()
.unstack(level=[1, 2], fill_value=0)
.sort_index(axis=1))
If the problem still persists, maybe some whitespace, best check converted columns to tuples.
q2=(nb.melt(id_vars='Center_Name', value_vars=cols)
.groupby([pd.Grouper(key='Center_Name'), 'variable', 'value'])
.size()
.unstack(level=[1, 2], fill_value=0))
print(q2.columns.tolist())