I have seen a strange behavior in PostgreSQL (PostGIS). I have two tables in PostGIS with geometry columns. one table is a grid and the other one is lines. I want to delete all grid cells that no line passes through them. In other words, I want to delete the rows from a table when that row has no spatial intersection with any rows of second table.
First, in a subquery, I find the ids of the rows that have any intersection. Then, I delete any row that its id is not in that returned list of ids.
DELETE FROM base_grid_916453354
WHERE id NOT IN
(
SELECT DISTINCT bg.id
FROM base_grid_916453354 bg, (SELECT * FROM tracks_heatmap_1000
LIMIT 100000) tr
WHERE bg.geom && tr.buffer
);
The following subquery returns in only 12 seconds
SELECT DISTINCT bg.id
FROM base_grid_916453354 bg, (SELECT * FROM tracks_heatmap_1000 LIMIT
100000) tr
WHERE bg.geom && tr.buffer
, while the whole query did not return even in 1 hour!!
I ran explain command and it is the result of it, but I cannot interpret it:
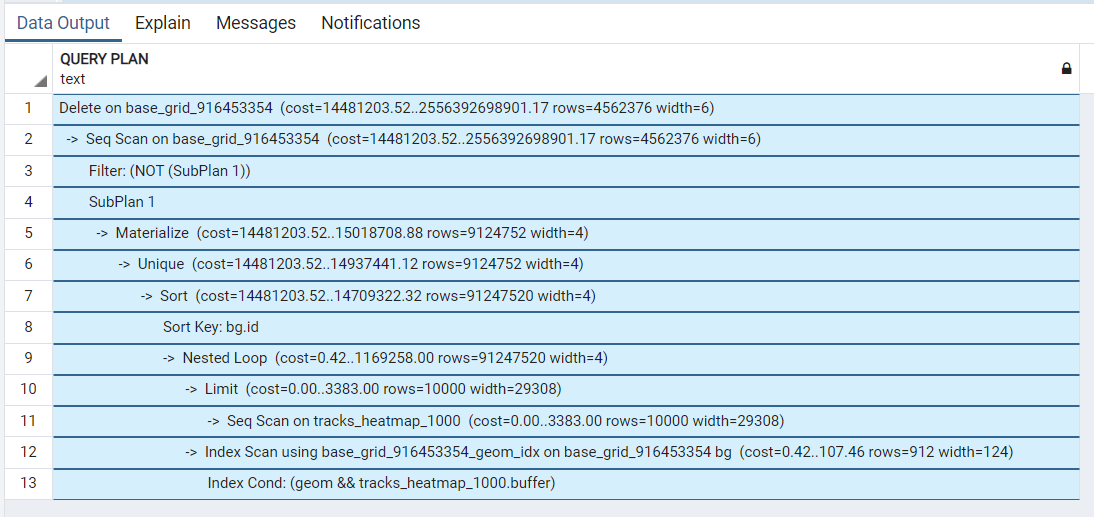
How can I improve this query and why deleting from the returned list takes so much of time?
It is very strange because the subquery is a spatial query between 2 tables of 9 million and 100k rows, while the delete part is just checking a list and deleting!! In my mind, the delete part is much much easier.
CodePudding user response:
Don't post text as images of text!
Increase work_mem until the subplan becomes a hashed subplan.
Or rewrite it to use 'NOT EXISTS' rather than NOT IN
CodePudding user response:
I found a fast way to do this query. As @jjanes said, I used EXISTS() function:
DELETE FROM base_grid_916453354 bg
WHERE NOT EXISTS
(
SELECT 1
FROM tracks_heatmap_1000 tr
WHERE bg.geom && tr.buffer
);
This query takes around 1 minute and it is acceptable for the size of my tables.