I succesfully instaled Spark and Pyspark in my machine, added path variables, etc. but keeps facing import problems.
This is the code:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.config("spark.hadoop.hive.exec.dynamic.partition", "true") \
.config("spark.hadoop.hive.exec.dynamic.partition.mode", "nonstrict") \
.enableHiveSupport() \
.getOrCreate()
And this is the error message:
"C:\...\Desktop\Clube\venv\Scripts\python.exe" "C:.../Desktop/Clube/services/ce_modelo_analise.py"
Traceback (most recent call last):
File "C:\...\Desktop\Clube\services\ce_modelo_analise.py", line 1, in <module>
from pyspark.sql import SparkSession
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\__init__.py", line 51, in <module>
from pyspark.context import SparkContext
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\context.py", line 31, in <module>
from pyspark import accumulators
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\accumulators.py", line 97, in <module>
from pyspark.serializers import read_int, PickleSerializer
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\serializers.py", line 71, in <module>
from pyspark import cloudpickle
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 145, in <module>
_cell_set_template_code = _make_cell_set_template_code()
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 126, in _make_cell_set_template_code
return types.CodeType(
TypeError: 'bytes' object cannot be interpreted as an integer
If I remove the import line, those problems disappear. As I said before, my path variables are set:
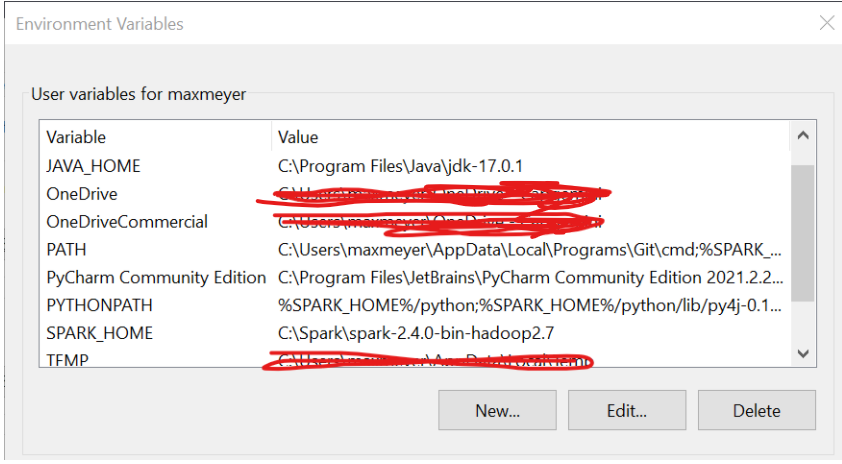
and
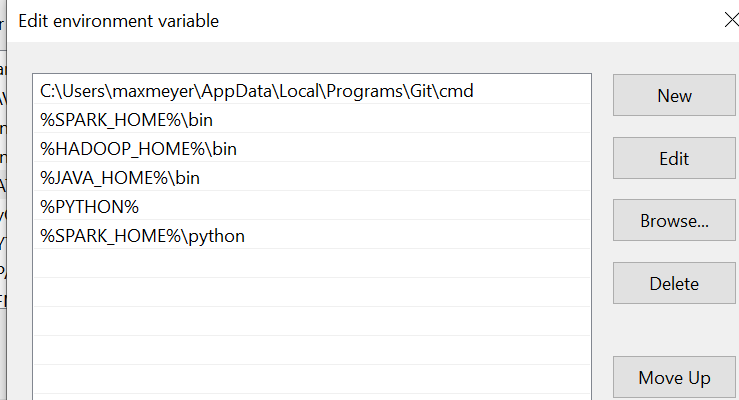
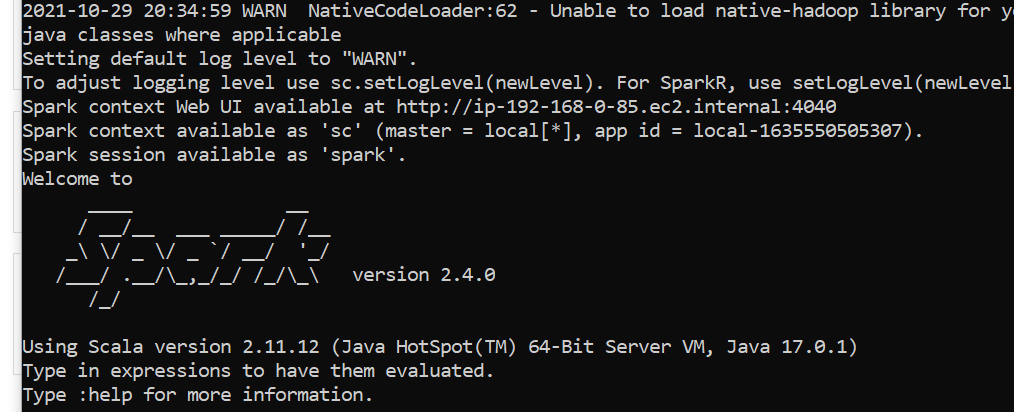
Also, Spark is running correctly in cmd:
CodePudding user response:
Going deeper I found the problem: I'm using Spark in version 2.4, which works with Python 3.7 tops.
As I was using Python 3.10, the problem was happening.
So if you're experiencing the same kind of issue, try to change your versions.