I am currently trying to crack a programming puzzle that has the very simple dataframe host with 2 columns named city and amenities (both are object datatype). Now, entries in both columns could be repeated multiple times. Below is the first few entries of host is beLOW
City Amenities Price($)
NYC {TV,"Wireless Internet", "Air conditioning","Smoke 8
detector",Essentials,"Lock on bedroom door"}
LA {"Wireless Internet",Kitchen,Washer,Dryer,"First aid
kit",Essentials,"Hair dryer","translation missing:
en.hosting_amenity_49","translation missing:
en.hosting_amenity_50"}
10
SF {TV,"Cable TV",Internet,"Wireless Internet",Kitchen,"Free
parking on premises","Pets live on this
property",Dog(s),"Indoor fireplace","Buzzer/wireless
intercom",Heating,Washer,Dryer,"Smoke detector","Carbon
monoxide detector","First aid kit","Safety card","Fire e
extinguisher",Essentials,Shampoo,"24-hour check-
in",Hangers,"Hair dryer",Iron,"Laptop friendly
workspace","translation missing:
en.hosting_amenity_49","translation missing:
en.hosting_amenity_50","Self Check-In",Lockbox} 15
NYC {"Wireless Internet","Air
conditioning",Kitchen,Heating,"Suitable for events","Smoke
detector","Carbon monoxide detector","First aid kit","Fire
extinguisher",Essentials,Shampoo,"Lock on bedroom
door",Hangers,"translation missing:
en.hosting_amenity_49","translation missing:
en.hosting_amenity_50"} 20
LA {TV,Internet,"Wireless Internet","Air
conditioning",Kitchen,"Free parking on
premises",Essentials,Shampoo,"translation missing:
en.hosting_amenity_49","translation missing:
en.hosting_amenity_50"}
LA {TV,"Cable TV",Internet,"Wireless Internet",Pool,Kitchen,"Free
parking on premises",Gym,Breakfast,"Hot tub","Indoor
fireplace",Heating,"Family/kid friendly",Washer,Dryer,"Smoke
detector","Carbon monoxide detector",Essentials,Shampoo,"Lock
on bedroom door",Hangers,"Private entrance"} 28
.....
Question. Output the city with the highest number of amenities.
My attempt. I tried using groupby() function to group it based on column city using host.groupby('city'). Now, I need to count successfully the number of elements in each set of Amenities. Since the data types are different, the len() function did not work because there are \ between each element in the set (for example, if I use host['amenities'][0], the output is "{TV,\"Wireless Internet\",\"Air conditioning\",\"Smoke detector\",\"Carbon monoxide detector\",Essentials,\"Lock on bedroom door\",Hangers,Iron}". Applying len() to this output would result in 134, which is clearly incorrect). I tried using host['amenities'][0].strip('\n') which removes the \, but the len() function still gives 134.
Can anyone please help me crack this problem?
To ddejohn's request:
Output of the host["Amenities"] = host["Amenities"].str.replace ...

Output of the second line of your code
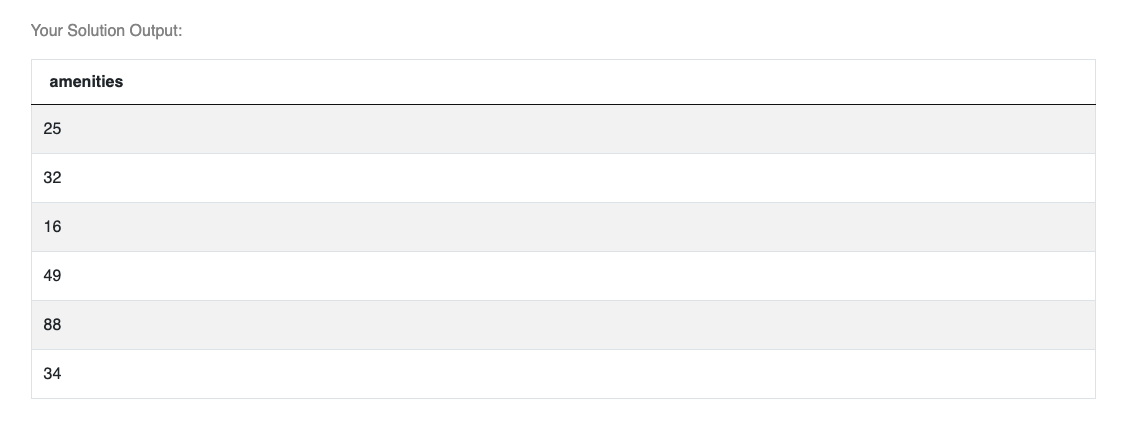
Original dataset travel
Output after travel.groupby('city')

CodePudding user response:
Solution
import functools
# Process the Amenities strings into sets of strings
host["amenities"] = host["amenities"].str.replace('["{}]', "", regex=True).str.split(",").apply(set)
# Groupby city, perform the set union to remove duplicates, and get count of unique amenities
amenities_by_city = host.groupby("city")["amenities"].apply(lambda x: len(functools.reduce(set.union, x))).reset_index()
Output:
city amenities
0 LA 27
1 NYC 17
2 SF 29
Getting the city with the max number of amenities is achieved with
city_with_most_amenities = amenities_by_city.query("amenities == amenities.max()")
Output:
city amenities
2 SF 29