I have the following issue:
I have to columns:
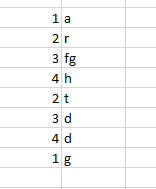
I have to create a list for each element from the first column. Precisely, I have to create the following lists: the first list for element 1 should contain [a, g] for element 2: [r, t], etc.
I tried something, but I something must not be correct
The first part of the code I used to find out which elements are duplicated in the first column
values = []
for i in range(2, ws11.max_row 1):
if ws11.cell(row=i, column=1).value in values:
pass
else:
values.append(ws11.cell(row=i, column=1).value)
print(values)
For the second part I wrote the following code:
listanew = []
for i in range(1, len(values) 1):
for j in range(2, ws11.max_row 1):
if ws11.cell(row=j, column=1).column == values[i-1]:
listanew.append(ws11.cell(row=j, column=2).value)
print(listanew)
When I tried to print my new list, I obtained an empty list. Could you give me a solution?
CodePudding user response:
I took the liberty to give names to the two columns; "A" and "B". Here is what you can do to group the data by column "A" and get a list of all the elements in "B":
df = pd.DataFrame({'A': [1,2,3,4,2,3,4,1],
'B': ['a', 'r', 'fg', 'h', 't', 'd', 'd', 'g']})
df = df.groupby('A')['B'].apply(list).reset_index()
CodePudding user response:
Use a dictionary (a defaultdict for shorter code):
from collections import defaultdict
d=defaultdict(list)
for row in range(1,ws11.max_row 1):
d[ws11.cell(row,1).value].append(ws11.cell(row,2).value)
d
defaultdict(<class 'list'>, {1: ['a', 'g'], 2: ['r', 't'], 3: ['fg', 'd'], 4: ['h', 'd']})