For context: thinking about a simplified "event store" table for use in our preexisting CRUD db.
The Events table would have a BIGINT IDENTITY primary key, which would also serve as the "position" of the event in the event log.
First of all because all the questions I could find with related keywords discussed gaps: I do not care about gaps, if the identity cache causes a jump from 12 to 1001, that is not an actual problem. The only important thing about gaps is that they should never be filled.
The question is: Can I ever run into a scenario where there are multiple inserts into the table from concurrent sources, and from the read side a row appears with identity value below an already existing identity value?
For example, if I create a service that wants to handle all rows inserted into the table, can I save locally the largest identity value of the already handled rows, and be sure, that if next time I ask for rows with identity values larger than the saved value, I will never miss a row that got inserted between existing identity values due to concurrency?
From my understanding, this is a sane and bomb proof assumption because the IDENTITY value is supposed to be filled out upon execution of the insert and there is no mechanism to reuse skipped values. But I dont have enough experience with SQL server to not question if there is some finicky edge case / specific implementation detail that
- breaks this assumption altogether?
- neccesiates some extra configuration to ensure this?
- if this works by default, is there some configuration / T-SQL command that could break it and should be avoided?
CodePudding user response:
Lower values will never be "filled in" unless someone reseeds via 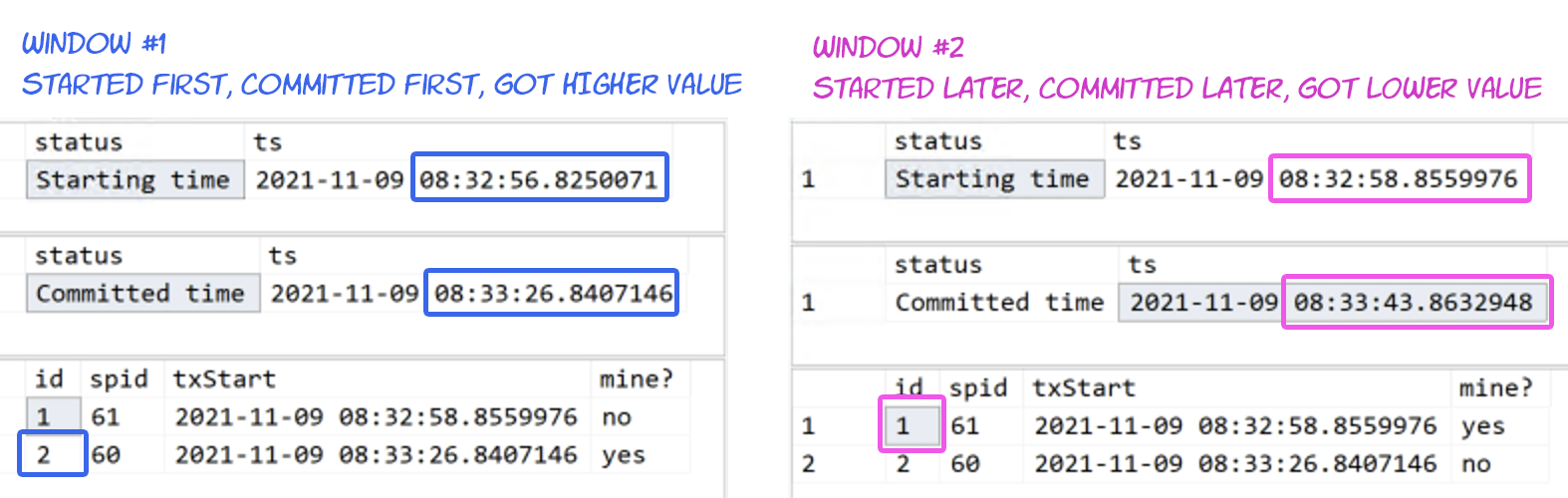
Without transactions or other delay possibilities in place, then no, first in wins, and the earliest insert will always have the lowest identity value. That said, it would be safer to rely on application timestamp if you need to be sure that app 1's event, which you know happened first, gets properly slotted before app 2's event, which you know happened a microsecond later. Order by that value you know, rather than relying on assumptions about the sequencing of arbitrary, surrogate identifier assignment. IMHO.