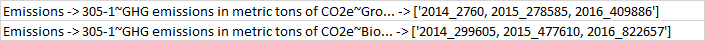I want to save a DataFrame as tab-delimited .csv
df.to_csv('df.csv', index=False, sep ='\t')
However, the 3rd column has a list object, which coincidentally holds commas: ,.
Because of this, my output df.csv has many columns. The first being 3 values, correctly delimited by tabs. The second and more are comma split values.
df (correctly: 3 columns):
0 1 \
0 Emissions 305-1~GHG emissions in metric tons of CO2e~Gro...
1 Emissions 305-1~GHG emissions in metric tons of CO2e~Bio...
2 Emissions 305-1~Direct (Scope 1) GHG emissions by gas~CO2
3 Emissions 305-1~Direct (Scope 1) GHG emissions by gas~N20
4 Emissions 305-1~Direct (Scope 1) GHG emissions by gas~HFCs
5 Emissions 305-1~Direct (Scope 1) GHG emissions by gas~PFCs
6 Emissions 305-1~Direct (Scope 1) GHG emissions by gas~SF6
7 Emissions 305-2~GHG Emissions in metric tons of CO2e~Gro...
8 Emissions 305-2~GHG Emissions in metric tons of CO2e~Gro...
9 Emissions 305-2~GHG Emissions in metric tons of CO2e~Tot...
10 Emissions 305-2~GHG Emissions in metric tons of CO2e~Tot...
11 Emissions 103-1~Explanation of the material topic and it...
12 Emissions 103-2~The management approach and its components
13 Emissions 103-3~Evaluation of the management approach
2
0 [2014_2760, 2015_278585, 2016_409886, 2017_972...
1 [2014_299605, 2015_477610, 2016_822657, 2017_8...
2 [2014_444055, 2015_730929, 2016_766490, 2017_8...
3 [2014_510811, 2015_583265, 2016_694522, 2017_7...
4 [2014_162816, 2015_199622, 2016_228775, 2017_3...
5 [2014_61824, 2015_569032, 2016_607814, 2017_77...
6 [2014_60442, 2015_64418, 2016_329338, 2017_784...
7 [2014_53078, 2015_500448, 2016_527776, 2017_61...
8 [2014_165580, 2015_557426, 2016_894641, 2017_9...
9 [2014_60142, 2015_84502, 2016_532996, 2017_893...
10 [2014_71762, 2015_72349, 2016_195351, 2017_624...
11 consumption rate fossil fuels coal oil emissio...
12 how evaluate companys environmental management...
13 evaluation effectiveness companys environmenta...
df.csv (incorrect, technically I want one column but for the original 3 column-values to be tab-delimited):

Simplified template example
df:
text | text | ['list', 'object', 'here', 'of', 'any', 'length']
text | text | ['foo', 'bar']
Desired .CSV [one literal column, but with values separated by tabs (->)]:
| text -> text -> ['list', 'object', 'here', 'of', 'any', 'length'] |
| text -> text -> ['foo', 'bar'] |
One column output, with values separated by tabs. No headers or indexes
How do I ensure that Pandas ignores the , of the list object?
Please let me know if I should provide any further details.
CodePudding user response:
FYI, you could just click "copy value" (semantics differ in each IDE) on your df in the variable viewer (again, name changes depends on IDE) to copy it's data in a way I could copy it, but I created a sample from what you have provided.
import pandas as pd
import csv
sample df:
df = pd.DataFrame({'col1': ['Emissions', 'Emissions'], 'col2': ['305-1~GHG emissions in metric tons of CO2e~Gro...', '305-1~GHG emissions in metric tons of CO2e~Bio...'], 'col3': [['2014_2760, 2015_278585, 2016_409886'], ['[2014_299605, 2015_477610, 2016_822657']]})
Now the trick here is to use the quoting parameter which according to the