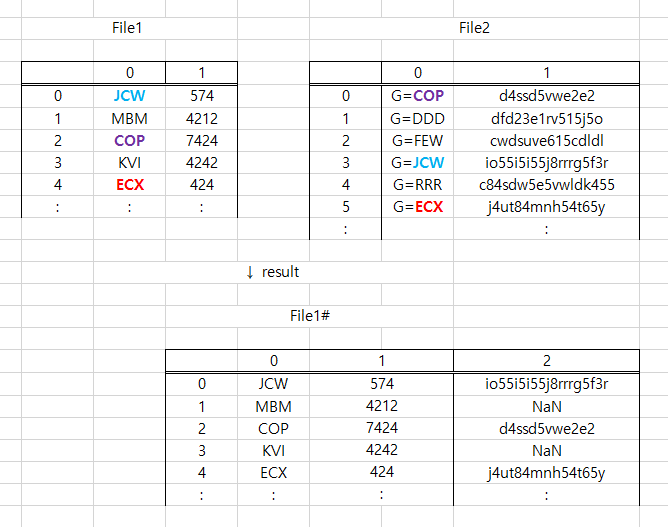
There are 2 files opened with Pandas. If there are common parts in the first column of two files (colored letters), I want to paste the data of the second column of second file into the matched part of the first file. And if there is no match, I want to write 'NaN'. Is there a way I can do in this situation?
File1
enter code here
0 1
0 JCW 574
1 MBM 4212
2 COP 7424
3 KVI 4242
4 ECX 424
File2
enter code here
0 1
0 G=COP d4ssd5vwe2e2
1 G=DDD dfd23e1rv515j5o
2 G=FEW cwdsuve615cdldl
3 G=JCW io55i5i55j8rrrg5f3r
4 G=RRR c84sdw5e5vwldk455
5 G=ECX j4ut84mnh54t65y
File1#
enter code here
0 1 2
0 JCW 574 io55i5i55j8rrrg5f3r
1 MBM 4212 NaN
2 COP 7424 d4ssd5vwe2e2
3 KVI 4242 NaN
4 ECX 424 j4ut84mnh54t65y
CodePudding user response:
Have a look at the concat-function of pandas using join='outer' (https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html). There is also this question and the answer to it that can help you.
It involves reindexing each of your data frames to use the column that is now called "0" as the index, and then joining two data frames based on their indices.
Also, can I suggest that you do not paste an image of your dataframes, but upload the data in a form that other people can test their suggestions.
CodePudding user response:
Use Series.str.extract for new Series for matched values by df1[0] values first and then merge with left join in DataFrame.merge:
df1 = pd.read_csv(file1)
df2 = pd.read_csv(file2)
s = df2[0].str.extract(f'({"|".join(df1[0])})', expand=False)
df = df1.merge(df2[[1]], how='left', left_on=0, right_on=s)
df.columns = np.arange(len(df.columns))
print (df)
0 1 2
0 JCW 574 io55i5i55j8rrrg5f3r
1 MBM 4212 NaN
2 COP 7424 d4ssd5vwe2e2
3 KVI 4242 NaN
4 ECX 424 j4ut84mnh54t65y
Or if need match last 3 values of column df1[0] use:
s = df2[0].str.extract(f'({"|".join(df1[0].str[-3:])})', expand=False)
df = df1.merge(df2[[1]], how='left', left_on=0, right_on=s)
df.columns = np.arange(len(df.columns))
print (df)