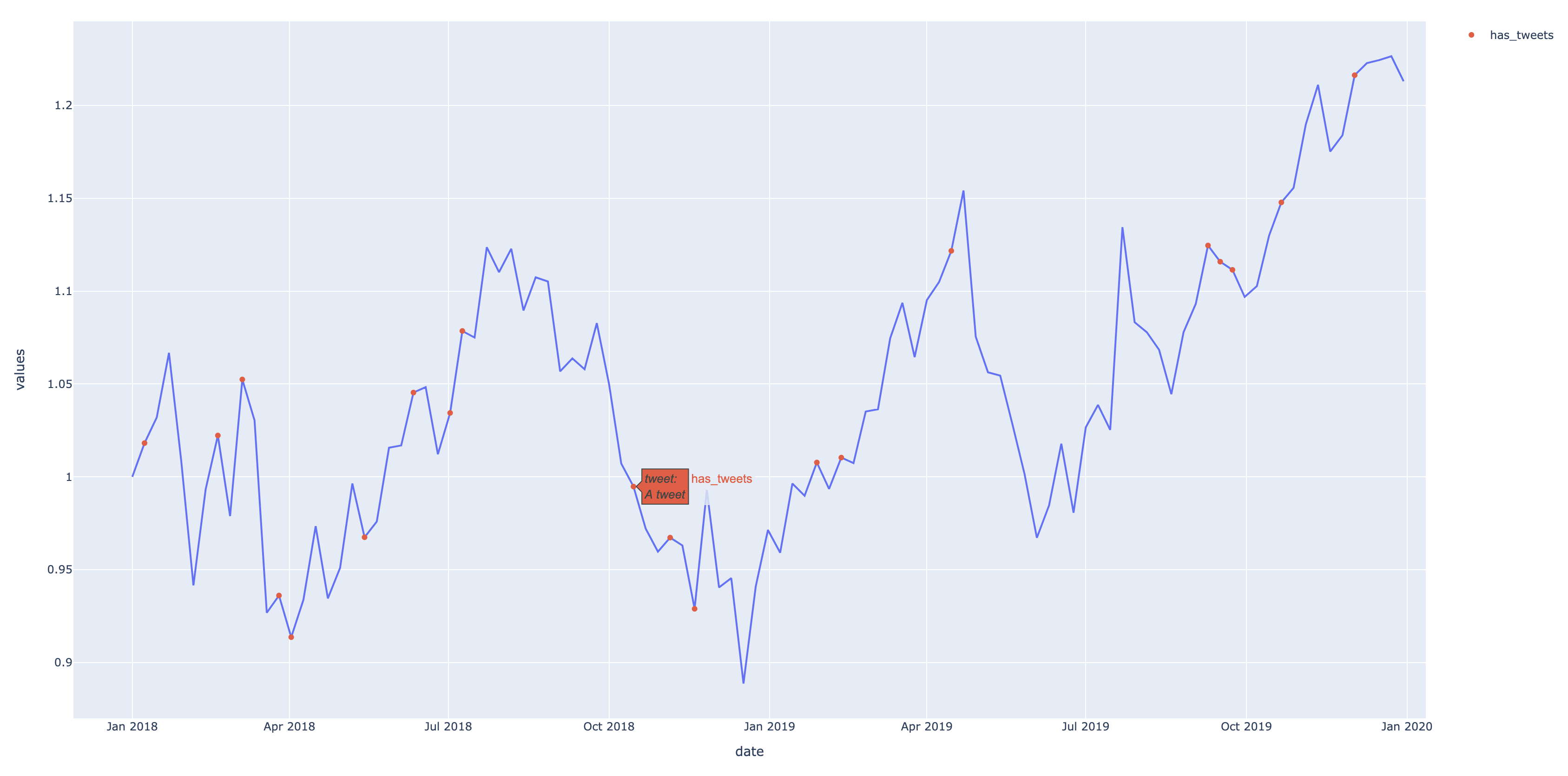
I have a plotly chart that I am trying to add tweets to hover information.
The dataframe itself contains 7000 rows (hourly crypto readings) and 139 tweets, labeled content. Of content, there are ~6861 rows of 'NaN' because content has 139 total tweets.
The code that I have below
fig = px.line(total_data, x = total_data.date,
y = total_data.doge_close)
fig.add_trace(
go.Scatter(
x=total_data[total_data.has_tweet==1].date,
y=total_data[total_data.has_tweet == 1['doge_close'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in total_data['content']],
name = 'has_tweets'))
fig.show()
produces this plot:
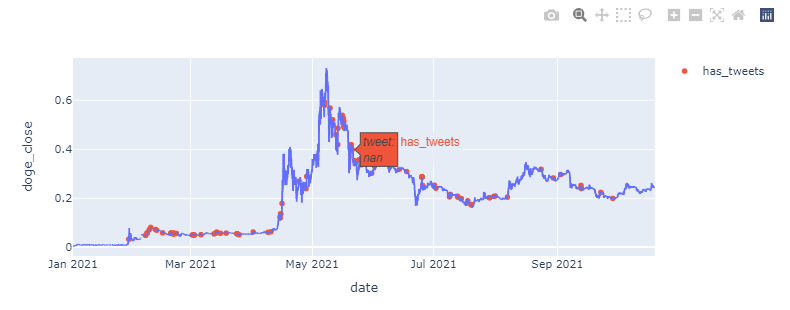
Where it says NaN, I'd like the actual content of the tweets at that time.
The "content" column can be loosely reproduced with this code below:
df = px.data.stocks().set_index('date')[['GOOG']].rename(columns={'GOOG':'values'})
df['has_tweet'] = df['tweet'].apply(lambda x: 0 if x != x else 1)
df['tweet'] = random.choices(['A tweet','Longer tweet', 'emoji','NaN'], weights=(5,10,5,80), k=len(df))
and can be generically reproduced with the code below:
import plotly.express as px
import plotly.graph_objects as go
import random
fig = px.line(df, x=df.index, y = 'values')
fig.add_trace(go.Scatter(x=df[df.has_tweet==1].index,
y = df[df.has_tweet==1]['values'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in df['tweet']],
name = 'has_tweets'))
fig.show()
Is there a way to filter out the 'NaN's from the dataframe in order to input the actual tweet content?
EDIT WITH SOLUTION
Thanks to a very kind commentor, I have figured out the solution and attached it below, for anyone in the future.
fig = px.line(total_data, x = total_data.date, y = total_data.doge_close)
fig.add_trace(go.Scatter(x=total_data[total_data.has_tweet==1].date,
y=total_data[total_data.has_tweet==1]['doge_close'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in total_data.loc[total_data['has_tweet']==1, 'content']],
name = 'has_tweets'))
fig.show()
which produces: 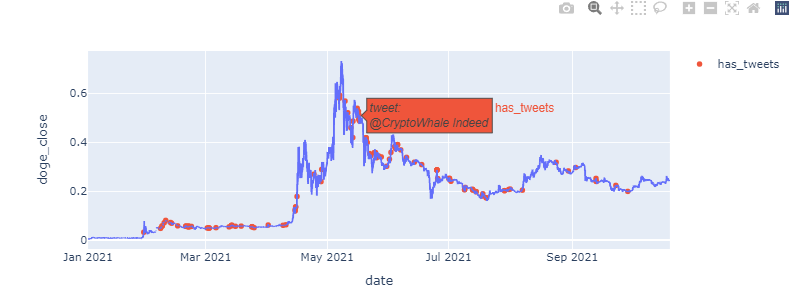
CodePudding user response:
Based on your comment, instead of randomly assigning 0 or 1 to the "has_tweet" column, it should be 0 or 1 based on whether the "tweet" column is NaN or not. Also instead of the string "NaN" I am using np.nan, but this may need to be modified depending on what your actual data looks like.
We can create some data similar to yours like this:
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
import random
random.seed(42)
df = px.data.stocks().set_index('date')[['GOOG']].rename(columns={'GOOG':'values'})
df['tweet'] = random.choices(['A tweet','Longer tweet', 'emoji',np.nan], weights=(5,10,5,80), k=len(df))
df['has_tweet'] = df['tweet'].apply(lambda x: 0 if x != x else 1)
Then I believe the only change we need to make is pass just the rows with tweets to the text argument:
fig = px.line(df, x=df.index, y = 'values')
fig.add_trace(go.Scatter(x=df[df.has_tweet==1].index,
y = df.loc[df.has_tweet==1]['values'],
mode = 'markers',
hovertemplate =
'<i>tweet:</i>' '<br>'
'<i>%{text}</i>',
text = [t for t in df.loc[df.has_tweet==1, 'tweet']],
name = 'has_tweets'))
fig.show()