I have a problem. I have the following dataframe. I want to count all the unique values. As you can see the problem is, that some of the words are uppercase or lowercase but are compleately the same thing i want to count. So in my case "Wifi" and "wifi" should be counted as 2. Same for the others. Is there a way i can do that by for example ignore the upper and lower case? And as you can see there are different writings for wifi (for example "Wifi 230 mb/s") is there a way to count the wifis when wifi is in the string?
d = {'host_id': [1, 1, 1, 2, 2, 3, 3, 3, 3],
'value': ['Hot Water', 'Wifi', 'Kitchen',
'Wifi', 'Hot Water',
'Coffe Maker', 'wifi', 'hot Water', 'Wifi 230 mb/s']}
df = pd.DataFrame(data=d)
print(df)
print(len(df[df['value'].str.contains("Wifi", case=False)]))
print(df['value'].unique())
print(len(df['value'].unique()))
[out]
host_id value
0 1 Hot Water
1 1 Wifi
2 1 Kitchen
3 2 Wifi
4 2 Hot Water
5 3 Coffe Maker
6 3 wifi
7 3 hot Water
8 3 Wifi 230 mb/s
4 # count wifi
['Hot Water' 'Wifi' 'Kitchen' 'Coffe Maker' 'wifi' 'hot Water'] # unique values
6 # len unique values
What [out] should look like:
value count
0 Hot Water 3
1 Wifi 4
2 Kitchen 1
3 Coffe Maker 1

CodePudding user response:
If there is problem only with wifi - possible another substrings use:
df['value'] = (df['value'].mask(df['value'].str.contains("Wifi", case=False), 'wifi')
.str.title())
print (df)
host_id value
0 1 Hot Water
1 1 Wifi
2 1 Kitchen
3 2 Wifi
4 2 Hot Water
5 3 Coffe Maker
6 3 Wifi
7 3 Hot Water
8 3 Wifi
print(df['value'].value_counts())
Wifi 4
Hot Water 3
Kitchen 1
Coffe Maker 1
Name: value, dtype: int64
print(df.groupby('value', sort=False).size().reset_index(name='count'))
value count
0 Hot Water 3
1 Wifi 4
2 Kitchen 1
3 Coffe Maker 1
EDIT:
#counts original values wit hconvert to uppercase first latters
s = df['value'].str.title().value_counts()
print (s)
Wifi 3
Hot Water 3
Wifi 230 Mb/S 1
Kitchen 1
Coffe Maker 1
Name: value, dtype: int64
#filter if counts greater like N
N = 2
good = s.index[s.gt(N)]
print (good)
Index(['Wifi', 'Hot Water'], dtype='object')
#extract values by list good
import re
pat = '|'.join(r"\b{}\b".format(x) for x in good)
df['new'] = df['value'].str.extract(rf'({pat})', expand=False, flags=re.I).str.title()
print (df)
host_id value new
0 1 Hot Water Hot Water
1 1 Wifi Wifi
2 1 Kitchen NaN
3 2 Wifi Wifi
4 2 Hot Water Hot Water
5 3 Coffe Maker NaN
6 3 wifi Wifi
7 3 hot Water Hot Water
8 3 Wifi 230 mb/s Wifi
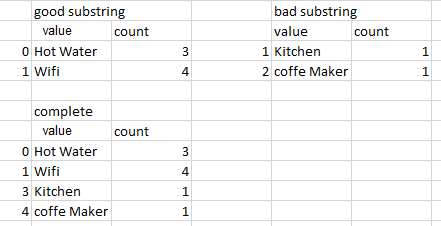
df1 = df.groupby('new', sort=False).size().reset_index(name='count')
print (df1)
new count
0 Hot Water 3
1 Wifi 4
#get values not matched to good list (working if no NaNs in original column)
df2 = df[df['new'].isna()].groupby('value', sort=False).size().reset_index(name='count')
print (df2)
value count
0 Kitchen 1
1 Coffe Maker 1
If need both:
df = pd.concat([df1, df2], ignore_index=True)
CodePudding user response:
Use str.lower() or str.upper() method on your list before comparing them. That should eliminate duplicates.
If you would like to eliminate typos or other similar strings you can use python-Levenshtein to calculate distance and set 'cut off point'
https://pypi.org/project/python-Levenshtein/