My data is having a repetitive pattern:
2021-11-17 10:59:10.880
SysState: 4, Events: 161403, EMS: 4, VDB: 2, TubeState: 0x02
BDR Mode: 1, BMS Ext: 2, BMS Int: 0, BdrStat: 00
CPU(%):16, CPUmax(%):47, task idx:3, CPUmaxIRQ(%):0
SOC:9973, SOH:100, LV?:0, HV?:0
3330mV 3333mV 3332mV 3332mV 3331mV 0 0
3331mV 3324mV 3325mV 3325mV 3328mV 0 0
3325mV 3321mV 3328mV 3328mV 3327mV 0 0
3329mV 0mV 0mV 0mV 0mV 0 0
BPV:53288, PLV:53241, BPC:0, PLC:0
AMBI:421, CONN:278, FETS:282, BMSC:274, BPA1:259, BPA2:237, BPA3:255
2021-11-17 10:59:13.80
SysState: 4, Events: 161407, EMS: 4, VDB: 3, TubeState: 0x08
BDR Mode: 4, BMS Ext: 3, BMS Int: 1, BdrStat: 00
CPU(%):12, CPUmax(%):47, task idx:3, CPUmaxIRQ(%):0
SOC:9973, SOH:100, LV?:0, HV?:0
3332mV 3331mV 3332mV 3332mV 3331mV 0 0
3331mV 3324mV 3325mV 3326mV 3328mV 0 0
3324mV 3321mV 3328mV 3328mV 3327mV 0 0
3329mV 0mV 0mV 0mV 0mV 0 0
BPV:53288, PLV:53277, BPC:23, PLC:0
AMBI:421, CONN:278, FETS:282, BMSC:276, BPA1:259, BPA2:237, BPA3:255
2021-11-17 10:59:15.280
SysState: 4, Events: 161407, EMS: 4, VDB: 3, TubeState: 0x08
BDR Mode: 4, BMS Ext: 3, BMS Int: 1, BdrStat: 00
CPU(%):11, CPUmax(%):47, task idx:3, CPUmaxIRQ(%):0
SOC:9973, SOH:100, LV?:0, HV?:0
3331mV 3332mV 3331mV 3332mV 3331mV 0 0
3331mV 3324mV 3325mV 3325mV 3328mV 0 0
3324mV 3322mV 3328mV 3328mV 3327mV 0 0
3331mV 0mV 0mV 0mV 0mV 0 0
BPV:53288, PLV:53259, BPC:47, PLC:47
AMBI:421, CONN:278, FETS:282, BMSC:276, BPA1:259, BPA2:237, BPA3:255
What I want to do is separate every value and make it a column starting from '2021-11-17 10:59:10.880' to 'BPA3:255'
| Index | Another header | Another header | Another header |
|---|---|---|---|
| 0 | 2021-11-17 10:59:10.880 | SysState: 4 | Events: 161403 |
| 1 | 2021-11-17 10:59:13.80 | SysState: 4 | Events: 1161407 |
so on and so forth..
what is have done so far:
The file was a .txt file and I converted it into csv first and then:
df = pd.read_csv('data.csv', sep=',' )
but it gives me ParserError: Error tokenizing data. Anybody knows how to solve this problem? with the sep= ';' or changing the text file to csv gives me the following output:
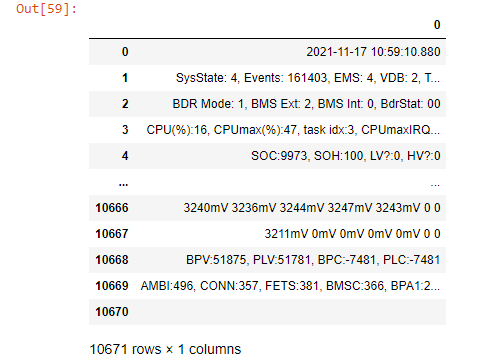
Is there a way to resolve this while parsing text file and not converting it into csv?
CodePudding user response:
Assuming you want only the date, the SysState and Events, an easy way is to extract the info using a regex.
I also assumed the file is not huge so I am loading all in memory, if this is not the case then you'll have to parse line by line.
with open('filename.csv') as f:
lines = f.read()
import re
regex = re.compile('(\d{4}-\d\d-\d\d \d\d:\d\d:\d\d\.\d )\nSysState: (\d ),\s Events: (\d ). ?')
df = pd.DataFrame(regex.findall(lines), columns=['datetime', 'SysState', 'Events'])
NB. I extracted only the numbers from the fields, but if you really want to have SysState: 4, etc. it is easy to add it in the capturing group
output:
datetime SysState Events
0 2021-11-17 10:59:10.880 4 161403
1 2021-11-17 10:59:13.80 4 161407
2 2021-11-17 10:59:15.280 4 161407