I have a set of more than 2000 issues on JIRA, and plan to copy all of those to a JSON file via Azure Data Factory. However, as Jira API only allows 100 issues per API link, i need to create multiple API links on dataset
(e.g: 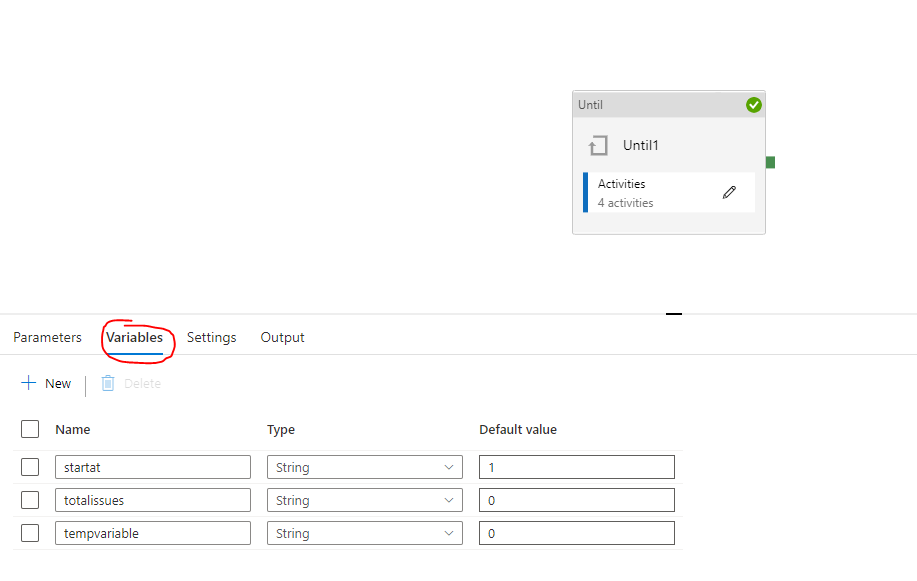
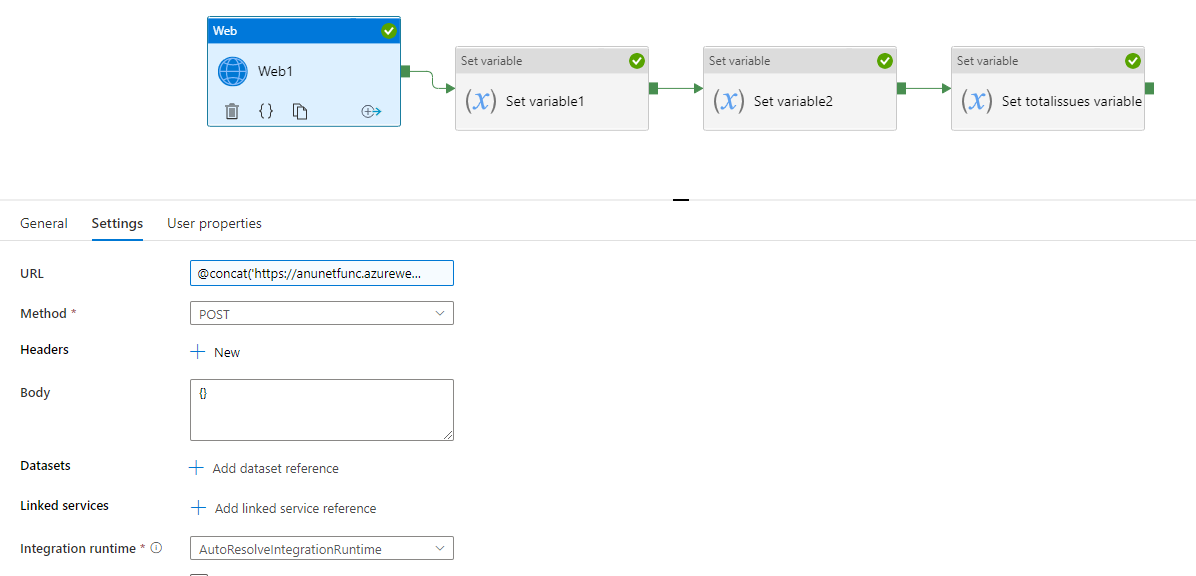
Your webactivity url will be a concat of the api url with the startat variable as shown. The maxresults can be hardcoded since these will always be 100.
@concat('https://anunetfunc.azurewebsites.net/api/PaginatedAPI?startat=',variables('startat'),'&maxresults=100')
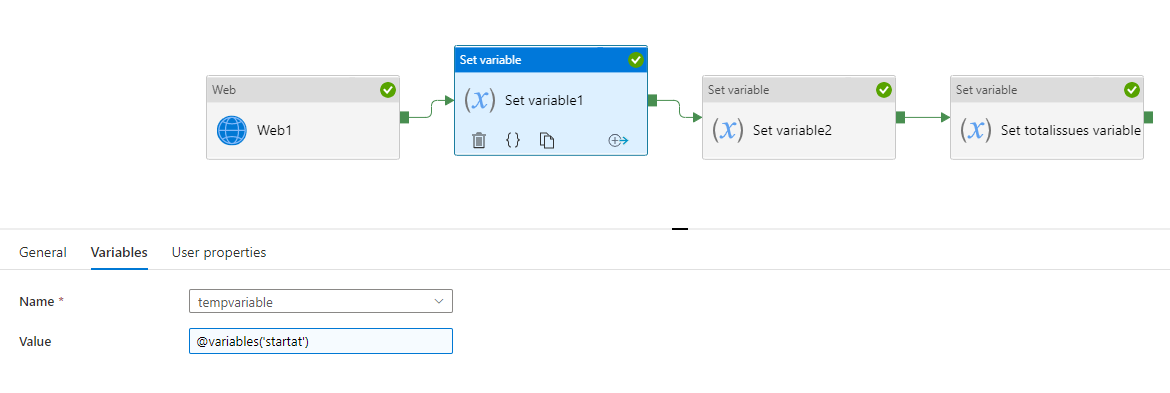
Now you need to set the tempvariable to @variables('startat'). This is because ADF dynamic content does allow you to include the variable that you are setting.
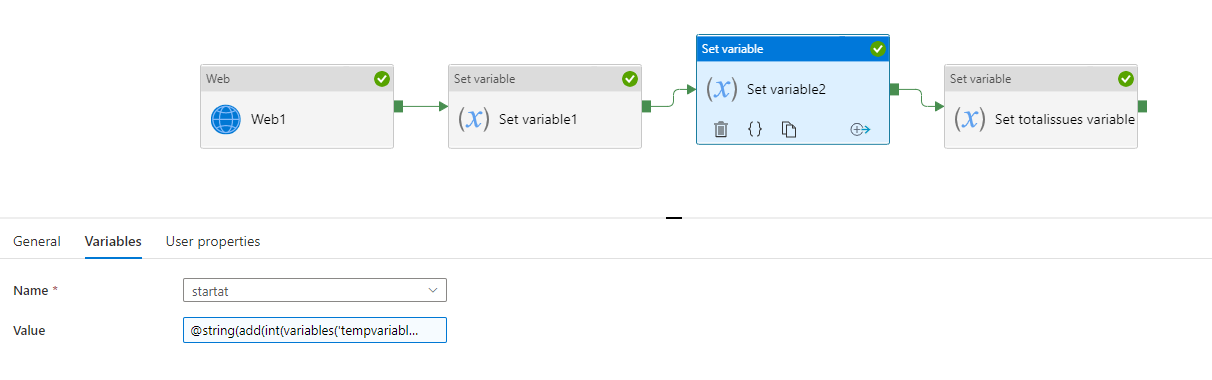
Next set the startat to temp 100. This is for the next page read.
@string(add(int(variables('tempvariable')),100))
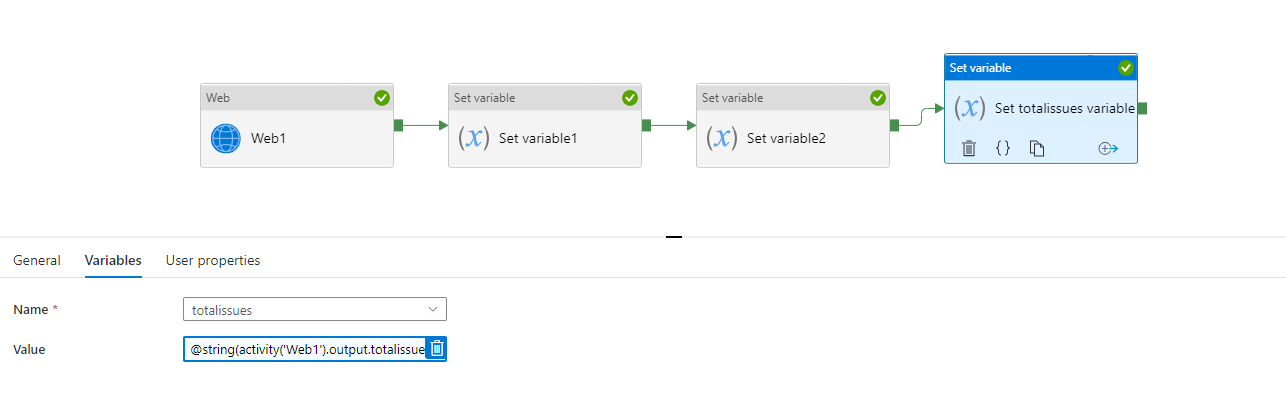
Lastly, set the total issues variable to the totalissues from the output of the 1st webactivity.
@string(activity('Web1').output.totalissues)
With this, the loop will execute only as many times to fetch all the issues. This is just a skeleton to show you how to do this. You still need to add activities to either bunch up all the issues before writing into storage or write separate files for each API call.