I'm wondering how queries with join operation perform when I have or don't have a foreign key. For example, given the following schema:
CREATE TABLE EMPLOYEE
(
ID BIGINT NOT NULL,
NAME VARCHAR(240),
DEPTID BIGINT
);
ALTER TABLE EMPLOYEE
ADD CONSTRAINT P_EMPLOYEE PRIMARY KEY (ID);
CREATE TABLE DEPARTMENT
(
ID BIGINT NOT NULL,
NAME VARCHAR(240)
);
ALTER TABLE DEPARTMENT
ADD CONSTRAINT P_DEPARTMENT PRIMARY KEY (ID);
INSERT INTO DEPARTMENT (ID, NAME)
VALUES (1, 'A'), (2, 'B'), (3, 'C');
INSERT INTO EMPLOYEE (ID, NAME, DEPTID)
VALUES (1, 'Bob', 1), (2, 'John', 1),
(3, 'Mike', 2), (4, 'Josh', 2),
(5, 'Lisa', 3), (6, 'Claire', 3);
ALTER TABLE EMPLOYEE
ADD CONSTRAINT F_EMP_DEP
FOREIGN KEY (DEPTID) REFERENCES DEPARTMENT (ID)
ON DELETE NO ACTION
ON UPDATE NO ACTION
ENFORCED
ENABLE QUERY OPTIMIZATION;
CREATE INDEX I_EMP_DEPTID ON EMPLOYEE (DEPTID);
And given I have the following query:
SELECT *
FROM EMPLOYEE E
JOIN DEPARTMENT D ON E.DEPTID = D.ID
WHERE D.NAME = 'A';
When I ask for the execution plan of it, it gives me the result below. It means the query is using the index I_EMP_DEPTID to improve the join operation.
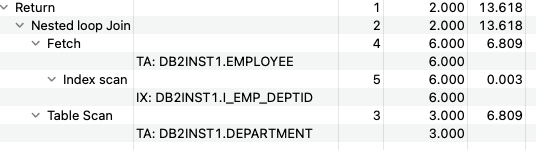
However, if I drop the index I_EMP_DEPTID.
DROP INDEX I_EMP_DEPTID;
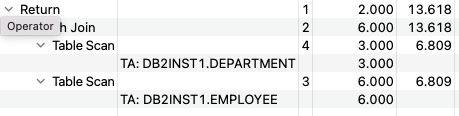
And ask for the execution plan again, this time it's running a table scan. See the image below.
If you read the FK docs from IBM about this subject it says that:
Referential integrity is imposed by adding foreign key (or referential) constraints to table and column definitions, and to create an index on all the foreign key columns. Once the index and foreign key constraints are defined, changes to the data within the tables and columns is checked against the defined constraint. Completion of the requested action depends on the result of the constraint checking.
So it means that in this case I have to create the FK and the INDEX as separated tasks, is that always correct? Does this concept apply to all SQL databases (e.g.: Oracle, Postgres, MySQL, SQL Server)? I mean is this a general concept that FKs don't automatically index the child columns or expect them to be indexed?
CodePudding user response:
It's important to clarify concepts first. A "foreign key" is the column, while a "foreign key constraint" is the integrity rule.
Now, to check the integrity rule engines are more efficient when there are indexes that help finding the related rows fast. In general, heap-based engines such as Oracle, DB2, PostgreSQL don't add the index automatically when you create a foreign key constraint. Clustered-index-based engines like MariaDB, MySQL, and SQL Server do this by default.
Those two models are quite different and in general heap-based engines tend to be more efficient. In these engines, however, the database designer needs to set up the helpful FK indexes manually. If the designer forgets to do this (happens often) then the performance of data modification statements and joins can worsen over time. On the flip side, an experienced designer can add highly customized indexes (to include covering indexes, specific column ordering, expressions, etc.) to serve many solutions with a minimal number of indexes. This requires more knowledge and in my experience most designers may not take full advantage of these features.
CodePudding user response:
Can't say much about other databases, but regarding MySQL it seems the index is created automatically on the referencing table, as documentation states:
MySQL requires indexes on foreign keys and referenced keys so that foreign key checks can be fast and not require a table scan. In the referencing table, there must be an index where the foreign key columns are listed as the first columns in the same order. Such an index is created on the referencing table automatically if it does not exist. This index might be silently dropped later if you create another index that can be used to enforce the foreign key constraint. index_name, if given, is used as described previously. Reference link