I have a pyspark dataframe of 13M rows and I would like to convert it to a pandas dataframe. The dataframe will then be resampled for further analysis at various frequencies such as 1sec, 1min, 10 mins depending on other parameters.
From literature [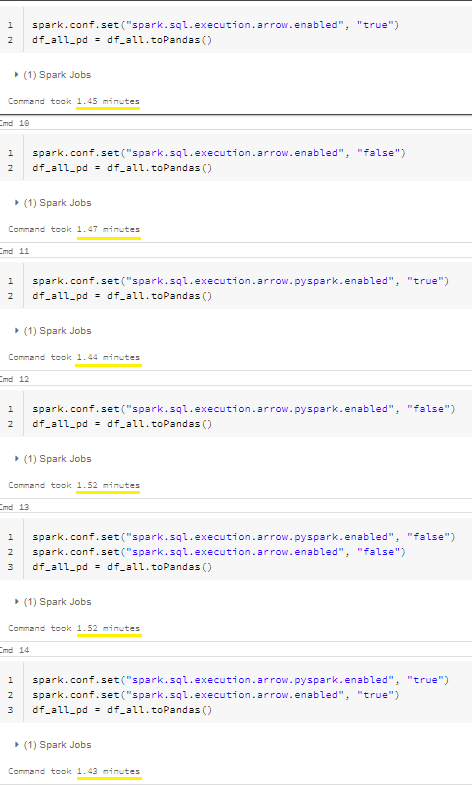
I have seen example where the change in processing time reduced from seconds to milliseconds [3]. I would like to know what I am doing wrong and how to optimize the code further. Thank you.
CodePudding user response:
Have you considered using Koala's? (A panda's clone that uses spark data frames so you can do panda operations on a spark data frame.)
CodePudding user response:
Depending on the version of spark and the notebook you are using you may not need to change this setting. Since Spark 2.3 spark uses arrow integration by default. Spark context once it is set is read only. (This ~2 minute operation could be your system recognizing you've changed a read only property and relaunching spark and re-running your commands.)
Respectfully, pandas is for small data, and spark is for big data. 13 million rows could be small data but your already complaining about performance, maybe you should stick with spark and use multiple executors/partitions?
You clearly can do this with Pandas, but should you?