I have data A and i want to divide it into training data and test data based on what we input, for example 50% or 70% but according to each class. Suppose I input 50% it will be like this:
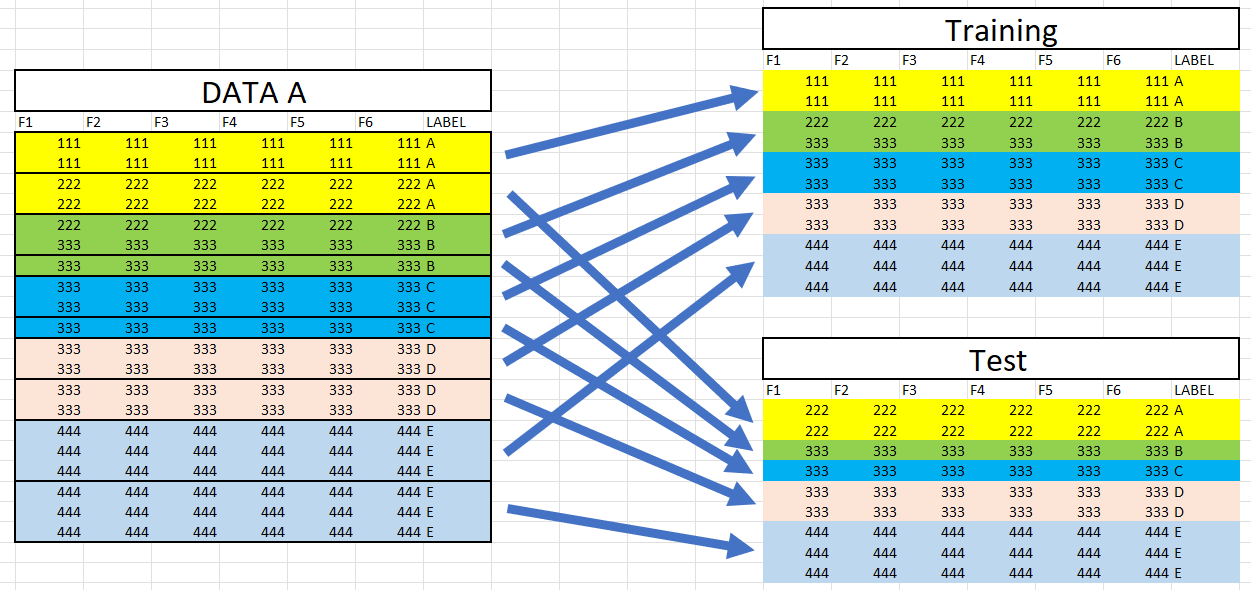
I tried using train_test_split but that method uses all the data, then divides it as much as we want instead of dividing it by label like i'm trying to find.
CodePudding user response:
I hope it may helpful to you
import pandas as pd
# create random data
d = {'label': [1, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, 2], 'value': [
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l"]}
df = pd.DataFrame(data=d) # creating dataframe
split_factor = 0.5
# initializing data frames
train_data = pd.DataFrame(columns=['label', 'value'])
test_data = pd.DataFrame(columns=['label', 'value'])
# get all unique labels
unique_labels = df['label'].unique()
# store length of every unique label
unique_lengths = {}
for uni in unique_labels:
unique_lengths[uni] = int(len(df[df.label == uni]) * split_factor) # updated on the suggestion on codingPhobia
for uni in unique_labels:
for _, row in df.iterrows():
if(row['label'] == uni):
if(unique_lengths[uni]): # if unique klength is not equal to 0
train_data = train_data.append({'label': row['label'], 'value': row['value']}, ignore_index=True)
unique_lengths[uni] = unique_lengths[uni] - 1 # minus unique lengths value
else:
test_data = test_data.append({'label': row['label'], 'value': row['value']}, ignore_index=True)
print('test data')
print(train_data)
print('train_data')
print(test_data)
CodePudding user response:
Mudasir Habib answer is perfect but you are missing one thing you need to wrap unique_lengths in int like
unique_lengths[uni] = int(len(df[df.label == uni]) * split_factor)
So the whole code will be
import pandas as pd
# create random data
d = {'label': [1, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, 2], 'value': [
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l"]}
df = pd.DataFrame(data=d) # creating dataframe
split_factor = 0.8
# initializing data frames
train_data = pd.DataFrame(columns=['label', 'value'])
test_data = pd.DataFrame(columns=['label', 'value'])
# get all unique labels
unique_labels = df['label'].unique()
# store length of every unique label
unique_lengths = {}
for uni in unique_labels:
unique_lengths[uni] = int(len(df[df.label == uni]) * split_factor)
for uni in unique_labels:
for _, row in df.iterrows():
if(row['label'] == uni):
if(unique_lengths[uni]): # if unique klength is not equal to 0
train_data = train_data.append({'label': row['label'], 'value': row['value']}, ignore_index=True)
unique_lengths[uni] = unique_lengths[uni] - 1 # minus unique lengths value
else:
test_data = test_data.append({'label': row['label'], 'value': row['value']}, ignore_index=True)
print('test data')
print(train_data)
print('train_data')
print(test_data)