I have a dataframe where I have six columns that are coded 1 for yes and 0 for no. There is also a column for year. The output I need is finding the conditional probability between each column being coded 1 according to year. I tried incorporating some suggestions from this post: 
Output I am seeking:
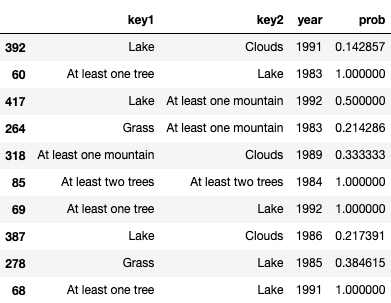
CodePudding user response:
To get your wide-formatted data into the long format of linked post, consider running melt and then run a self merge by year for all pairwise combinations (avoiding same keys and reverse duplicates). Then calculate as linked post shows:
long_df = current_df.melt(
id_vars = "Year",
var_name = "Key",
value_name = "Value"
)
pairwise_df = (
long_df.merge(
long_df,
on = "Year",
suffixes = ["1", "2"]
).query("Key1 < Key2")
.assign(
Both_Occur = lambda x: np.where(
(x["Value1"] == 1) & (x["Value2"] == 1),
1,
0
)
)
)
prob_df = (
(pairwise_df.groupby(["Year", "Key1", "Key2"])["Both_Occur"].value_counts() /
pairwise_df.groupby(["Year", "Key1", "Key2"])["Both_Occur"].count()
).to_frame(name = "Prob")
.reset_index()
.query("Both_Occur == 1")
.drop(["Both_Occur"], axis = "columns")
)
To demonstrate with reproducible data
import numpy as np
import pandas as pd
np.random.seed(112621)
random_df = pd.DataFrame({
'At least one tree': np.random.randint(0, 2, 100),
'At least two trees': np.random.randint(0, 2, 100),
'Clouds': np.random.randint(0, 2, 100),
'Grass': np.random.randint(0, 2, 100),
'At least one mounain': np.random.randint(0, 2, 100),
'Lake': np.random.randint(0, 2, 100),
'Year': np.random.randint(1983, 1995, 100)
})
# ...same code as above...
prob_df
Year Key1 Key2 Prob
0 1983 At least one mounain At least one tree 0.555556
2 1983 At least one mounain At least two trees 0.555556
5 1983 At least one mounain Clouds 0.416667
6 1983 At least one mounain Grass 0.555556
8 1983 At least one mounain Lake 0.555556
.. ... ... ... ...
351 1994 At least two trees Grass 0.490000
353 1994 At least two trees Lake 0.420000
355 1994 Clouds Grass 0.280000
357 1994 Clouds Lake 0.240000
359 1994 Grass Lake 0.420000