I made a checkout function in my library management system. It aims to let the user choose books from the given treeview: 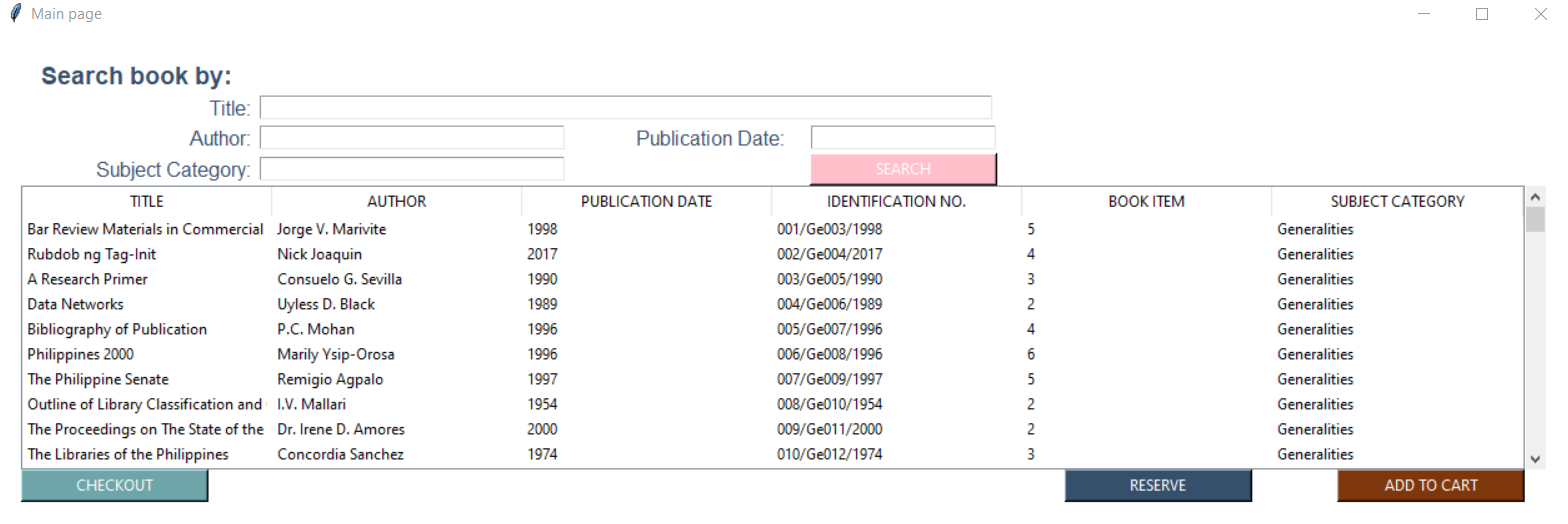 I aim to get the row of data that the user clicks on and pressed "add to cart" to another window with a treeview:
I aim to get the row of data that the user clicks on and pressed "add to cart" to another window with a treeview: 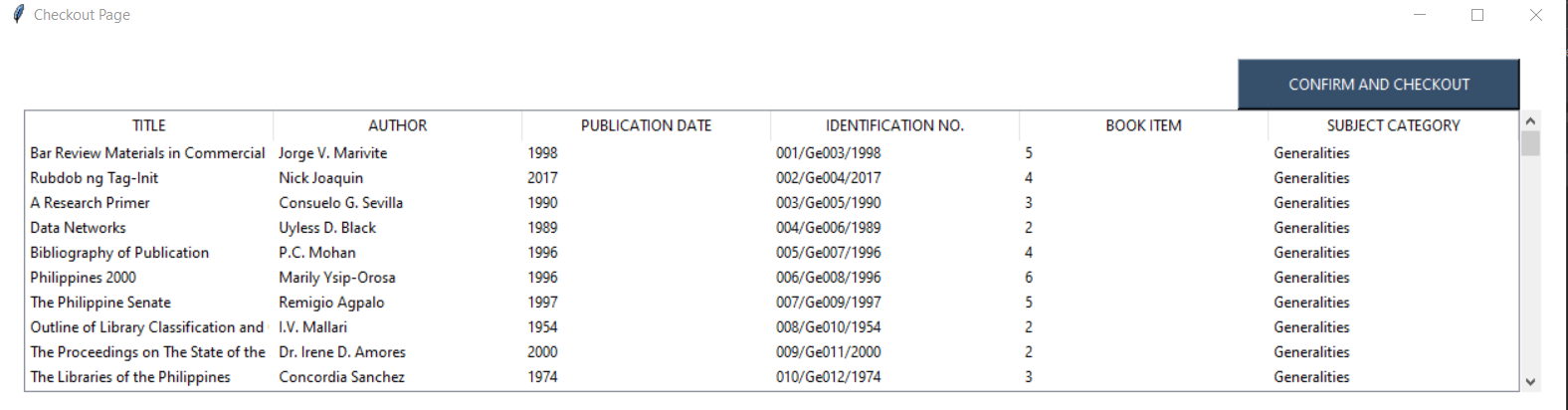 . Only adding the specific row of books data that they chose from the main page. Here is my treeview code:
. Only adding the specific row of books data that they chose from the main page. Here is my treeview code:
reserve_button = Button(text="RESERVE" ,fg=WHITE, bg=NAVY_BLUE, width=20, command=reserve)
reserve_button.grid(column=5,row=5)
checkout_button = Button(text="CHECKOUT", fg=WHITE,bg="#6DA5A9",width=20,command=checkout_page)
checkout_button.grid(column=0,row=5,sticky="w")
search_button = Button(text="SEARCH", fg=WHITE,bg="pink", width=20, command=search)
search_button.grid(column=3,row=3)
add_to_cart = Button(text="ADD TO CART", fg=WHITE,bg="#7E370C", width=20,command=add_to_cart_f)
add_to_cart.grid(column=7, row=5,sticky="e")
tree = ttk.Treeview()
books_data = pandas.read_csv("List of Books - Sheet1 (3).csv")
df_column = books_data.columns.values
print(len(df_column))
print(df_column)
tree["column"] = list(books_data.columns)
tree["show"] = "headings"
vsb = ttk.Scrollbar(orient="vertical", command=tree.yview())
vsb.grid(column=8, row=4, sticky="ns")
tree.configure(yscrollcommand=vsb.set)
for column in tree['column']:
tree.heading(column,text=column)
df_rows = books_data.to_numpy().tolist()
for row in df_rows:
tree.insert("","end",values=row)
tree.grid(column=0,row=4,columnspan=8)
CodePudding user response:
The short answer
I created an example project that would use this:
import tkinter as tk
import tkinter.ttk as ttk
import sys
from numpy import select
import pandas
# https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv
df = pandas.read_csv('./booklist.csv')
df.columns = df.columns.str.replace('.', '', regex=False)
df.columns = df.columns.str.replace(' ', '_', regex=False)
df.head()
class main_window:
def __init__(self, root):
self.root = root
root.title("Treeview Search Example")
# Create DataFrame for this window
self.build_df = df.copy()
self.checkout_ids = []
# INITIALIZE TREEVIEW SCROLLVIEW
self.tree = ttk.Treeview(root, columns=list(df.columns.values), show='headings')
self.tree.grid(row=1, column=0, sticky='nsew')
# https://stackoverflow.com/a/41880534/5210078
vsb = ttk.Scrollbar(root, orient="vertical", command=self.tree.yview)
vsb.grid(row=1, column=1, sticky='ns')
self.tree.configure(yscrollcommand=vsb.set)
for column in self.tree['column']:
self.tree.heading(column,text=column)
df_rows = df.to_numpy().tolist()
for row in df_rows:
if row[4] != 0:
self.tree.insert("","end",values=row)
# ADD SEARCH BOXES
search_frame = tk.Frame(root)
search_frame.grid(row=0, column=0, columnspan=2, sticky='nsew')
tk.Label(search_frame, text="TITLE:").grid(row=0, column=0)
tk.Label(search_frame, text="AUTHOR:").grid(row=0, column=2)
tk.Label(search_frame, text="IDENTIFICATION NO:").grid(row=0, column=4)
tk.Label(search_frame, text="SUBJECT CATEGORY:").grid(row=0, column=6)
# Add Search boxes
self.title_ent = tk.Entry(search_frame)
self.title_ent.grid(row=0, column=1)
self.author_ent = tk.Entry(search_frame)
self.author_ent.grid(row=0, column=3)
self.identifaction_ent = tk.Entry(search_frame)
self.identifaction_ent.grid(row=0, column=5)
self.category_ent = tk.Entry(search_frame)
self.category_ent.grid(row=0, column=7)
tk.Button(search_frame, text="Search", command=self.search).grid(row=0, column=10)
tk.Button(search_frame, text="Reseve", command=self.reserve).grid(row=0, column=11)
def search(self):
# https://stackoverflow.com/a/27068344/5210078
self.tree.delete(*self.tree.get_children())
self.build_df = df.copy()
# https://stackoverflow.com/a/56157729/5210078
entries = [
self.title_ent,
self.author_ent,
self.identifaction_ent,
self.category_ent
]
if entries[0].get():
self.build_df = self.build_df[self.build_df.TITLE.str.contains(entries[0].get())]
if entries[1].get():
self.build_df = self.build_df[self.build_df.AUTHOR.str.contains(entries[1].get())]
if entries[2].get():
self.build_df = self.build_df[self.build_df.SUBJECT_CATEGORY.str.contains(entries[2].get())]
if entries[3].get():
self.build_df = self.build_df[self.build_df.PUBLICATION_DATE == (entries[3].get())]
df_rows = self.build_df.to_numpy().tolist()
for row in df_rows:
print(row)
if row[4] != 0:
self.tree.insert("","end",values=row)
def reserve(self):
selected = self.tree.item(self.tree.focus())
if selected['values']:
# get the id
book_id = selected['values'][3]
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
if book_id_val < 1:
return 0
else:
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
if __name__ == '__main__':
main = tk.Tk()
main_window(main)
main.mainloop()
sys.exit()
Where booklist.csv looks like the following:
TITLE,AUTHOR,PUBLICATION DATE,IDENTIFICATION NO.,BOOK ITEM,SUBJECT CATEGORY
Book 1,Author 1,1923,001/geo003/1993,4,Awesome
Book 2,Author 2,1924,001/geo003/1994,5,Awesome
Book 3,Author 3,1925,001/geo003/1995,6,Awesome
Book 4,Author 4,1926,001/geo003/1996,7,Awesome
Book 5,Author 5,1927,001/geo003/1997,8,Awesome
Book 6,Author 6,1928,001/geo003/1998,9,Awesome
Book 7,Author 7,1929,001/geo003/1999,10,Awesome
Book 8,Author 8,1930,001/geo003/2000,11,Awesome
Book 9,Author 9,1931,001/geo003/2001,12,Awesome
Book 10,Author 10,1932,001/geo003/2002,13,Awesome
The explanation
df = pandas.read_csv('./booklist.csv')
df.columns = df.columns.str.replace('.', '', regex=False)
df.columns = df.columns.str.replace(' ', '_', regex=False)
Clean-up the csv file, so there are no spaces or . in column names (pandas really doesn't like them and they are not necessary)
class main_window:
def __init__(self, root):
self.root = root
root.title("Treeview Search Example")
# Create DataFrame for this window
self.build_df = df.copy()
self.checkout_ids = []
Initialize a class main_window which contains the code you need. And create two variables build_df and checkout_ids, the checkout_ids will be a list containing your current "basket". The build_df holds a temporary copy of your DataFrame (df), which can be filtered and moved around as you like, without effecting the original DataFrame.
# INITIALIZE TREEVIEW SCROLLVIEW
self.tree = ttk.Treeview(root, columns=list(df.columns.values), show='headings')
self.tree.grid(row=1, column=0, sticky='nsew')
# https://stackoverflow.com/a/41880534/5210078
vsb = ttk.Scrollbar(root, orient="vertical", command=self.tree.yview)
vsb.grid(row=1, column=1, sticky='ns')
self.tree.configure(yscrollcommand=vsb.set)
for column in self.tree['column']:
self.tree.heading(column,text=column)
df_rows = df.to_numpy().tolist()
for row in df_rows:
if row[4] != 0:
self.tree.insert("","end",values=row)
# ADD SEARCH BOXES
search_frame = tk.Frame(root)
search_frame.grid(row=0, column=0, columnspan=2, sticky='nsew')
tk.Label(search_frame, text="TITLE:").grid(row=0, column=0)
tk.Label(search_frame, text="AUTHOR:").grid(row=0, column=2)
tk.Label(search_frame, text="IDENTIFICATION NO:").grid(row=0, column=4)
tk.Label(search_frame, text="SUBJECT CATEGORY:").grid(row=0, column=6)
# Add Search boxes
self.title_ent = tk.Entry(search_frame)
self.title_ent.grid(row=0, column=1)
self.author_ent = tk.Entry(search_frame)
self.author_ent.grid(row=0, column=3)
self.identifaction_ent = tk.Entry(search_frame)
self.identifaction_ent.grid(row=0, column=5)
self.category_ent = tk.Entry(search_frame)
self.category_ent.grid(row=0, column=7)
tk.Button(search_frame, text="Search", command=self.search).grid(row=0, column=10)
tk.Button(search_frame, text="Reseve", command=self.reserve).grid(row=0, column=11)
Initialize the main UI, this holds things like your entry boxes. Importantly, the if statement: if row[4] != 0: is used because if there are no books available, there is no reason to display them!
def search(self):
# https://stackoverflow.com/a/27068344/5210078
self.tree.delete(*self.tree.get_children())
self.build_df = df.copy()
# https://stackoverflow.com/a/56157729/5210078
entries = [
self.title_ent,
self.author_ent,
self.identifaction_ent,
self.category_ent
]
if entries[0].get():
self.build_df = self.build_df[self.build_df.TITLE.str.contains(entries[0].get())]
if entries[1].get():
self.build_df = self.build_df[self.build_df.AUTHOR.str.contains(entries[1].get())]
if entries[2].get():
self.build_df = self.build_df[self.build_df.SUBJECT_CATEGORY.str.contains(entries[2].get())]
if entries[3].get():
self.build_df = self.build_df[self.build_df.PUBLICATION_DATE == (entries[3].get())]
df_rows = self.build_df.to_numpy().tolist()
for row in df_rows:
print(row)
if row[4] != 0:
self.tree.insert("","end",values=row)
The search system remains the same as the previous answer! Other than the if statement functionality added as seen earlier!
The reserve function
def reserve(self):
selected = self.tree.item(self.tree.focus())
if selected['values']:
# get the id
book_id = selected['values'][3]
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
if book_id_val < 1:
return 0
else:
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
selected = self.tree.item(self.tree.focus())
Gets the currently selected item from the self.tree
if selected['values']:
If there is a selected item (stops errors when nothing is selected)
book_id = selected['values'][3]
Takes the book_id (4th column) from the selected item and stores a copy of it.
book_id_val = df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'].to_numpy().tolist()[0]
Finds the book in the original DataFrame and get how many books there are of it!
if book_id_val < 1:
return 0
If there are no books available, don't do anything, (this is a fallback error-catcher because it isn't entirely necessary).
self.checkout_ids.append(book_id)
df.loc[df['IDENTIFICATION_NO'] == book_id, 'BOOK_ITEM'] = book_id_val - 1
self.search()
- Store a copy of the
idinto thecheckout_idslist - Decrease the number of available books by one
- Reload the treeview!