I'm am currently using selenium to take the product information from Sneider electric and this is currently the error I am receiving:
selenium.common.exceptions.NoSuchElementException: Message:
no such element: Unable to locate element:
{"method":"xpath","selector":"/html/body/div[2]/main/div[5]/ul/li/div/div/div/div/div/ul/li[1]/div/div/div[2]/div[2]/section/div/product-cards-wrapper//div/ul/li[1]/product-card/article/div/div[1]/product-card-main-info//div/pes-router-link[2]/a/h3"}
Currently, the website I am trying to pull this information from is this URL:
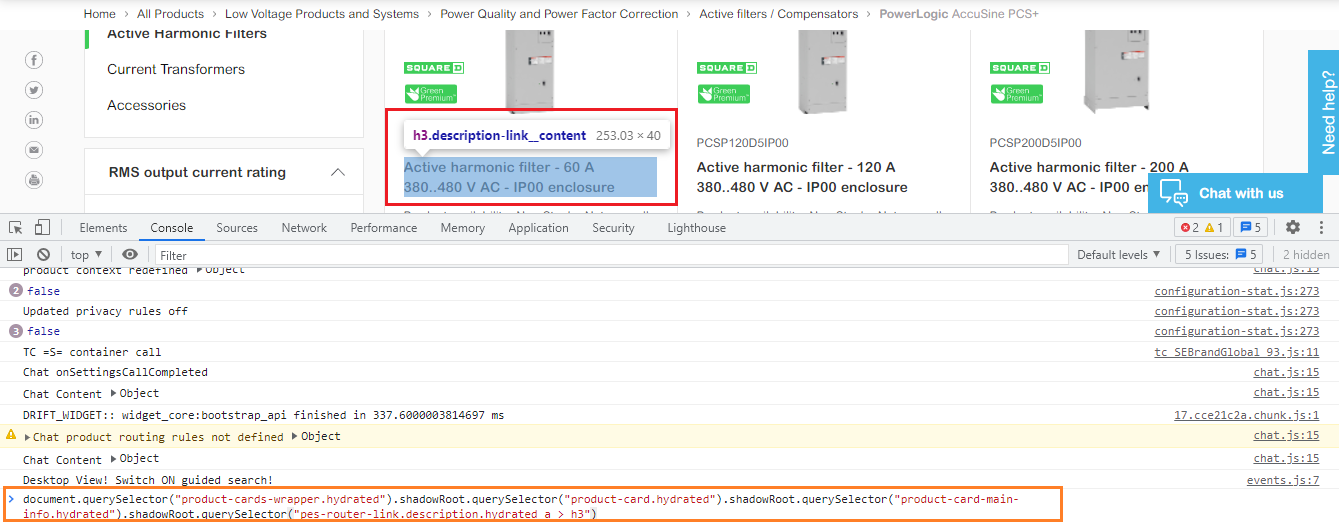
Solution
Tto extract the desired text you need to use shadowRoot.querySelector() and you can use the following Locator Strategy:
driver.get("https://www.se.com/us/en/product-range/63426-powerlogic-accusine-pcs+/?N=4176697776&No=0&Nrpp=12")
time.sleep(5)
description = driver.execute_script('''return document.querySelector("product-cards-wrapper.hydrated").shadowRoot.querySelector("product-card.hydrated").shadowRoot.querySelector("product-card-main-info.hydrated").shadowRoot.querySelector("pes-router-link.description.hydrated a > h3")''')
print(description.text)
Console Output:
Active harmonic filter - 60 A 380..480 V AC - IP00 enclosure
References
You can find a couple of relevant detailed discussions in:
- How to locate the First name field within shadow-root (open) within the website https://www.virustotal.com using Selenium and Python
- How to get past a cookie agreement page using Python and Selenium?
- Unable to locate the Sign In element within #shadow-root (open) using Selenium and Python
CodePudding user response:
First of all, don't use absolute XPath. Use relative xpath. It starts with // Do share a screenshot here and point to the element which you're trying to interact with. Happy automation