I have a post-joined datasets where the columns are identical except the right side has new and corrected data and a .TODROP suffix appended at the end of the column's name.
So the dataset looks something like this:
df = spark.createDataFrame(
[
(1, "Mary", 133, "Pizza", "Mary", 13, "Pizza"),
(2, "Jimmy", 8, "Hamburger", None, None, None),
(3, None, None, None, "Carl", 6, "Cake")
],
["guid", "name", "age", "fav_food", "name.TODROP", "age.TODROP", "fav_food.TODROP"]
)

I'm trying to slide over the right side columns to the left side columns if there is value:
if df['name.TODROP'].isNotNull():
df['name'] = df['name.TODROP']
if df['age.TODROP'].isNotNull():
df['age'] = df['age.TODROP']
if df['fav_food.TODROP'].isNotNull():
df['fav_food'] = df['fav_food.TODROP']
However, the problem is that the brute-force solution will take a lot longer with my real dataset because it has a lot more columns than this example. And I'm also getting this error so it wasn't working out anyway...
"pyspark.sql.utils.AnalysisException: Can't extract value from name#1527: need struct type but got string;"
Another attempt where I try to do it in a loop:
col_list = []
suffix = ".TODROP"
for x in df.columns:
if x.endswith(suffix) == False:
col_list.append(x)
for x in col_list:
df[x] = df[x suffix]
Same error as above.
Goal:
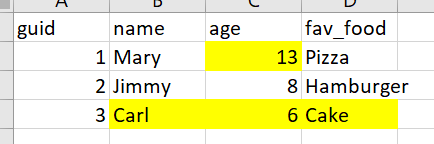
Can someone point me in the right direction? Thank you.
CodePudding user response:
First of all, your dot representation of the column name makes confusion for the struct type of column. Be aware that. I have concatenate the column name with backtick and it prevents the misleading column type.
suffix = '.TODROP'
cols1 = list(filter(lambda c: not(c.endswith(suffix)), df.columns))
cols2 = list(filter(lambda c: c.endswith(suffix), df.columns))
for c in cols1[1:]:
df = df.withColumn(c, f.coalesce(f.col(c), f.col('`' c suffix '`')))
df = df.drop(*cols2)
df.show()
---- ----- --- ---------
|guid| name|age| fav_food|
---- ----- --- ---------
| 1| Mary|133| Pizza|
| 2|Jimmy| 8|Hamburger|
| 3| Carl| 6| Cake|
---- ----- --- ---------