Suppose I have the following markdown list items:
- [x] Example of a completed task.
- [x] ! Example of a completed task.
- [x] ? Example of a completed task.
I am interested to parse that item using regex and extract the following group captures:
$1: the left[and the right]brackets when the symbolxis in-between$2: the symbolxin between the brackets[and]$3: the modifier!that follows after[x]$4: the modifier?that follows after[x]$5: the text that follows[x]without a modifier, e.g.,[x] This is targeted.$6: the text that follows[x] !$7: the text that follows[x] ?
After a lot of trial-and-error using online parsers, I came up with the following:
((?<=x)\]|\[(?=x]))|((?<=\[)x(?=\]))|((?<=\[x\]\s)!(?=\s))|((?<=\[x\]\s)\?(?=\s))|((?<=\[x\]\s)[^!?].*)|((?<=\[x\]\s!\s).*)|((?<=\[x\]\s\?\s).*)
To make the regex above more readable, these are the capture groups listed one by one:
$1:((?<=x)\]|\[(?=x]))$2:((?<=\[)x(?=\]))$3:((?<=\[x\]\s)!(?=\s))$4:((?<=\[x\]\s)\?(?=\s))$5:((?<=\[x\]\s)[^!?].*)$6:((?<=\[x\]\s!\s).*)$7:((?<=\[x\]\s\?\s).*)
This is most likely not the best way to do it, but at least it seems to capture what I want:
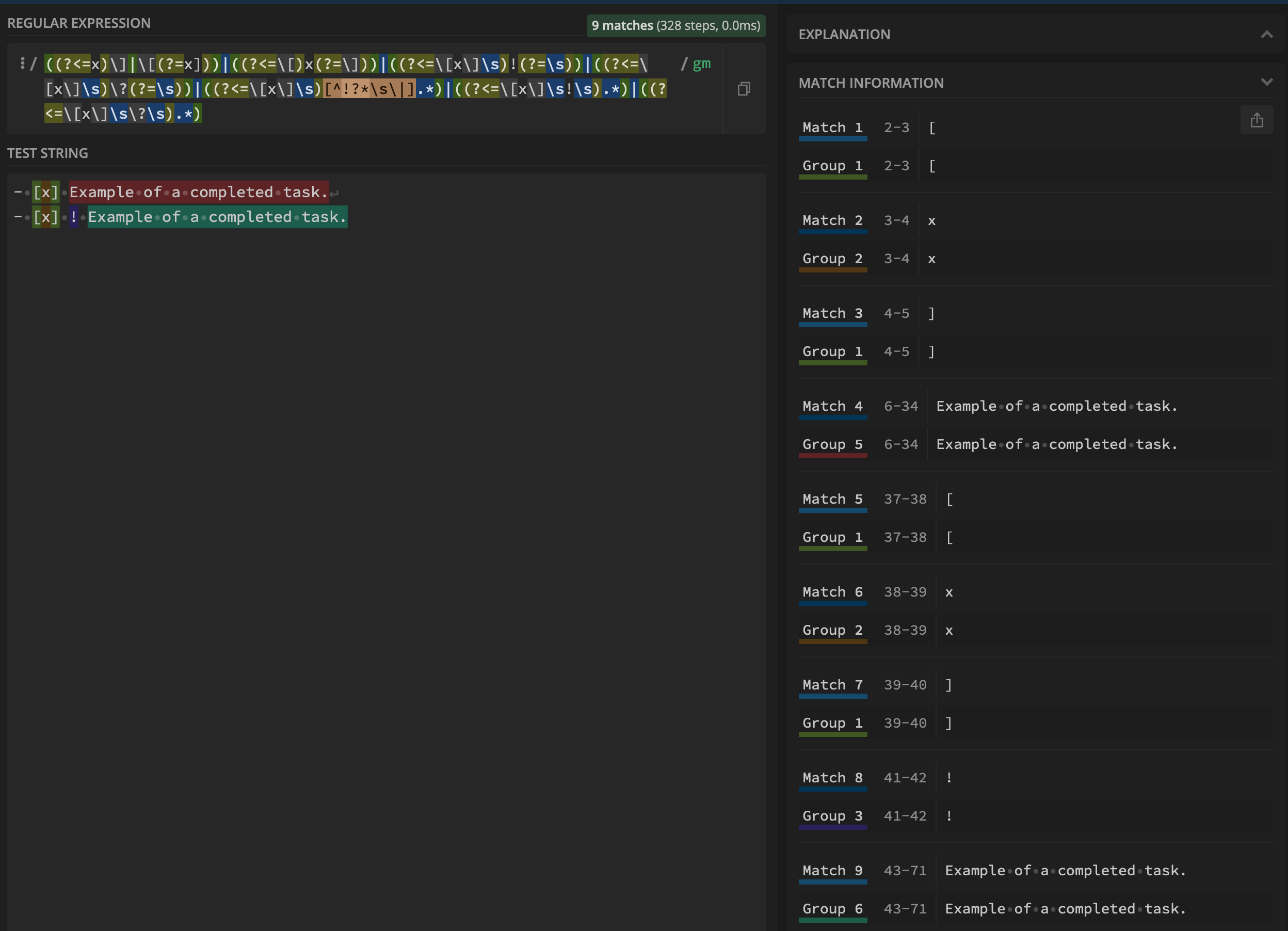
I would like to extend that regex to capture lines in a markdown table that
looks like this:
| | Task name | Plan | Actual | File |
| :---- | :-------------------------------------- | :---------: | :---------: | :------------: |
| [x] | Task one with a reasonably long name. | 08:00-08:45 | 08:00-09:00 | [[task-one]] |
| [x] ! | Task two with a reasonably long name. | 09:00-09:30 | | [[task-two]] |
| [x] ? | Task three with a reasonably long name. | 11:00-13:00 | | [[task-three]] |
More specifically, I am interested in having the same group captures as above, but I would like to exclude the table grid (i.e., the |). So, groups $1 to $4 should stay the same, but groups $5 to $7 should capture the text, excluding the |, e.g., like in the selection below:
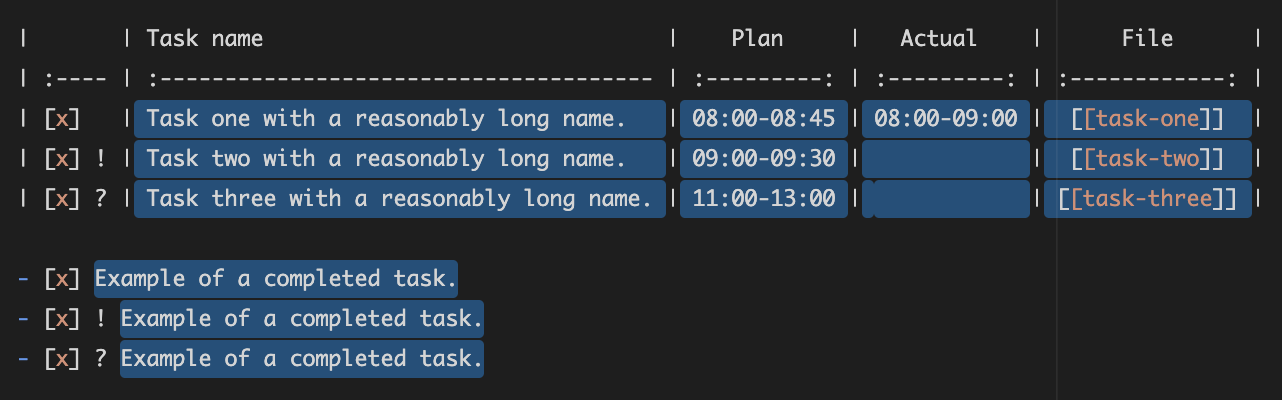
Do you have any ideas on how I can adjust, for example, the regex for group $5 to exclude the |. I have endlessly tried all sorts of negations (e.g., [^\|]). I am using Oniguruma regular expressions.
CodePudding user response:
If I understood correctly, for a line like this
| [x] ! | Task two with a reasonably long name. | 09:00-09:30 | | [[task-two]] |
you want the output after the pipe sign [4 parts]
- [x] !
- Task two with a reasonably long name
- 09:00-09:30
- [[task-two]]
Then maybe you can try the following
((?<=\|\s)([^|] ))
There are 2 parts to the expression.
- (?<=\|\s) Positive look behind
- ([^|] ) Any character except the pipe. Which means it will greedily get hold of the text, time etc
CodePudding user response:
You can use
((?<=x)]|\[(?=x]))|((?<=\[)x(?=]))|((?<=\[x]\s)!(?=\s))|(?<=\[x]\s)(\?)(?=\s)|(?:\G(?!\A)\||(?<=\[x]\s[?!\s]\s\|))\K([^|\n]*)(?=\|)
See the regex101 PCRE and a Ruby (Onigmo/Oniguruma) demos.
What is added? The (?:\G(?!\A)\||(?<=\[x]\s[?!\s]\s\|))\K([^|\n]*)(?=\|) part:
(?:- start of a non-capturing group (a custom boundary here, we'll match...)\G(?!\A)\|- either the end of the previous match and a|char (i.e.|must immediately follow the previous match),|(?<=\[x]\s[?!\s]\s\|)- or a location that is immediately preceded with[x]a whitespace a?,!or whitespace a whitespace and|char
)- end of the group\K- match reset operator that removes the text matched so far from the overall match memory buffer([^|\n]*)- zero or more chars other than|and a line feed char(?=\|)- a|char must appear immediately to the right of the current location.