First, sorry for my poor english. Actually, i make a script who find data on amazon webpage. I need to scrape asin on amazon webpage, with python and selenium. I've made this code for to scrape asin:
firstResult = driver.find_element_by_css_selector('div[data-index="1"]>div')
asin = firstResult.get_attribute('data-asin')
But its not work, i have some errors on results:
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"div[data-index="1"]>div"}
(Session info: headless chrome=96.0.4664.45)
The part of source code who has asin number, on webpage (ASIN is highlighted):
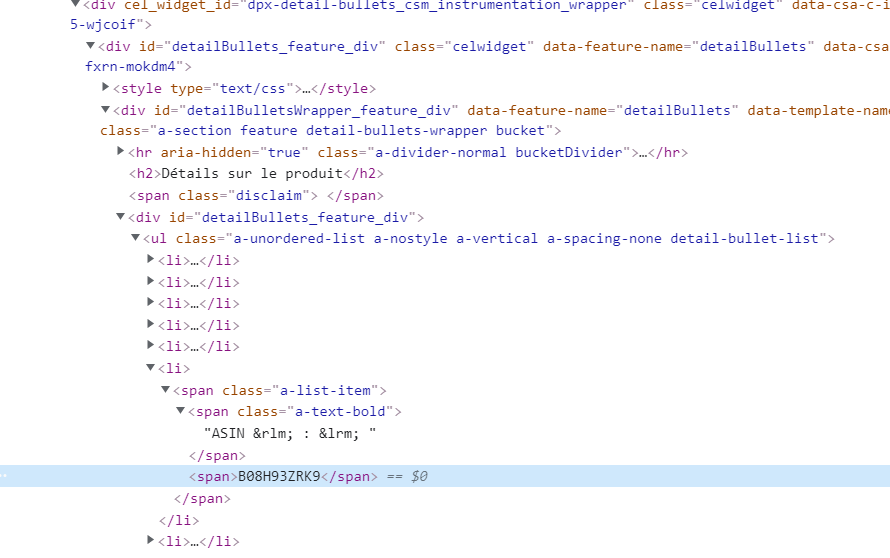
Anyone know how to make for to scrape this ASIN in python with selenium please? Ty for help!
CodePudding user response:
You could wait and look for the span which is located beside that tag.
wait=WebDriverWait(driver, 60)
driver.get('https://www.amazon.fr/PlayStation-Édition-Standard-DualSense-Couleur/dp/B08H93ZRK9')
elem=wait.until(EC.presence_of_element_located((By.XPATH," //span[@class='a-list-item' and contains (.,'ASIN')]//span[2]")))
print(elem.text)
Imports:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Outputs:
B08H93ZRK9
Another thing is that url actually has the same value at the end. Which could be obtained which a simple string manipulation of the driver.current_url,
https://www.amazon.fr/PlayStation-Édition-Standard-DualSense-Couleur/dp/ B08H93ZRK9