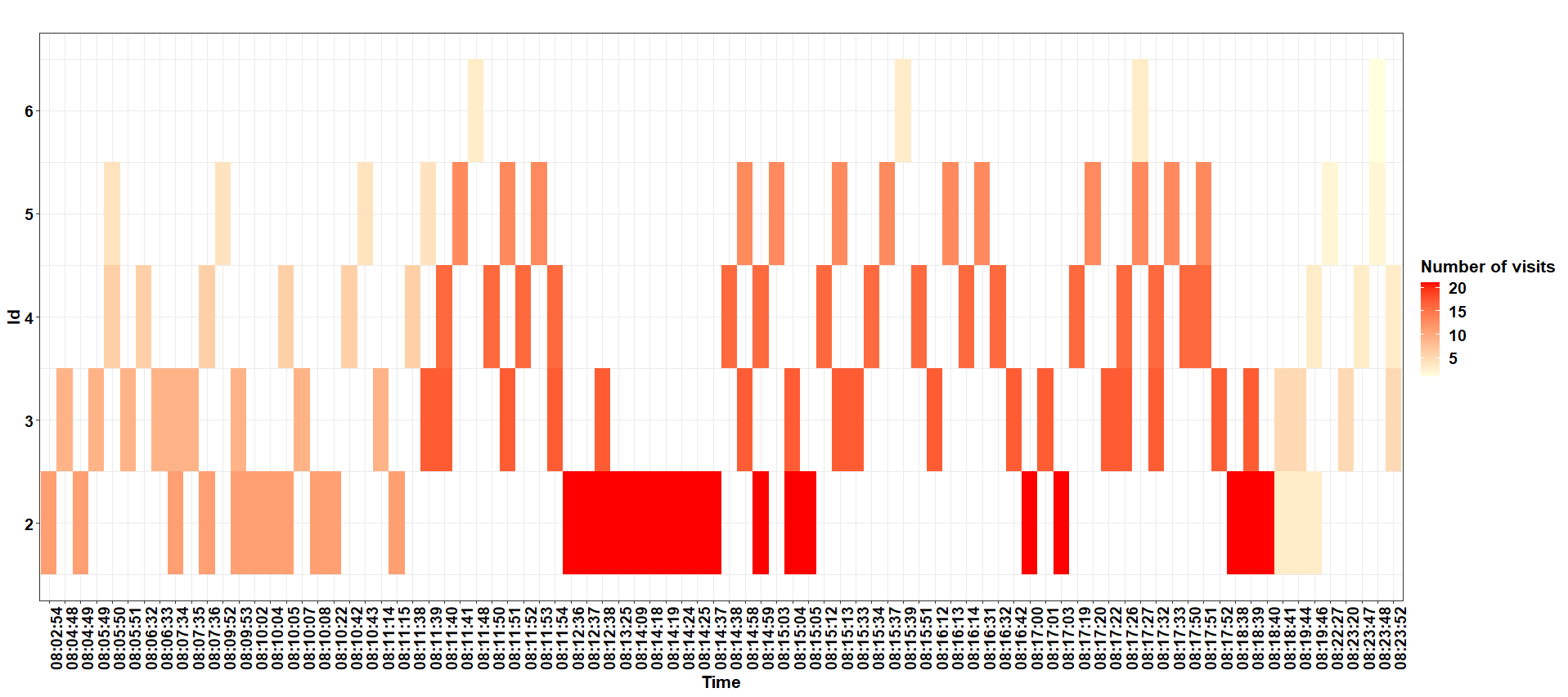
I have a large dataset which logs id across the day at a specific location
What I would like to do is plot the cumulative number of visits by each individual id over the time period the data were collected.
A sample of the data looks like this, the full data set has visits over a number of days.
I've tried some variations using cumsum but just can't get it to work.
dput(df)
structure(list(date = c("06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021", "06/01/2021",
"06/01/2021", "06/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021", "07/01/2021",
"07/01/2021", "07/01/2021", "08/01/2021", "08/01/2021", "08/01/2021",
"08/01/2021", "08/01/2021", "08/01/2021", "08/01/2021", "08/01/2021",
"08/01/2021", "08/01/2021", "08/01/2021", "08/01/2021", "08/01/2021",
"08/01/2021"), time = c("08:02:54", "08:04:48", "08:04:49", "08:05:49",
"08:05:50", "08:05:50", "08:05:51", "08:06:32", "08:06:33", "08:07:34",
"08:07:34", "08:07:35", "08:07:36", "08:07:36", "08:09:52", "08:09:53",
"08:09:53", "08:10:02", "08:10:04", "08:10:05", "08:10:05", "08:10:07",
"08:10:08", "08:10:22", "08:10:42", "08:10:43", "08:11:14", "08:11:15",
"08:11:38", "08:11:39", "08:11:39", "08:11:40", "08:11:40", "08:11:41",
"08:11:48", "08:11:50", "08:11:51", "08:11:51", "08:11:52", "08:11:53",
"08:11:54", "08:11:54", "08:12:36", "08:12:37", "08:12:38", "08:12:38",
"08:13:25", "08:13:25", "08:14:09", "08:14:18", "08:14:19", "08:14:24",
"08:14:24", "08:14:25", "08:14:37", "08:14:38", "08:14:58", "08:14:58",
"08:14:59", "08:14:59", "08:15:03", "08:15:04", "08:15:04", "08:15:05",
"08:15:12", "08:15:13", "08:15:13", "08:15:33", "08:15:34", "08:15:37",
"08:15:39", "08:15:51", "08:16:12", "08:16:13", "08:16:14", "08:16:31",
"08:16:32", "08:16:42", "08:17:00", "08:17:00", "08:17:01", "08:17:03",
"08:17:19", "08:17:20", "08:17:22", "08:17:26", "08:17:26", "08:17:27",
"08:17:27", "08:17:32", "08:17:32", "08:17:33", "08:17:50", "08:17:51",
"08:17:51", "08:17:52", "08:18:38", "08:18:39", "08:18:39", "08:18:40",
"08:18:41", "08:18:41", "08:19:44", "08:19:44", "08:19:46", "08:19:46",
"08:22:27", "08:23:20", "08:23:20", "08:23:47", "08:23:48", "08:23:48",
"08:23:52", "08:23:52"), id = c(2L, 3L, 2L, 3L, 4L, 5L, 3L, 4L,
3L, 2L, 3L, 3L, 2L, 4L, 5L, 2L, 3L, 2L, 2L, 2L, 4L, 3L, 2L, 2L,
4L, 5L, 3L, 2L, 4L, 5L, 3L, 3L, 4L, 5L, 6L, 4L, 3L, 5L, 4L, 5L,
4L, 3L, 2L, 2L, 3L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 4L,
5L, 3L, 2L, 4L, 5L, 3L, 2L, 2L, 4L, 5L, 3L, 3L, 4L, 5L, 6L, 4L,
3L, 5L, 4L, 5L, 4L, 3L, 2L, 2L, 3L, 2L, 4L, 5L, 3L, 3L, 4L, 5L,
6L, 4L, 3L, 5L, 4L, 5L, 4L, 3L, 2L, 2L, 3L, 2L, 3L, 2L, 2L, 3L,
2L, 4L, 5L, 3L, 3L, 4L, 5L, 6L, 4L, 3L)), class = "data.frame", row.names = c(NA,
-114L))
head(df)
date time id
1 06/01/2021 08:02:54 2
2 06/01/2021 08:04:48 3
3 06/01/2021 08:04:49 2
4 06/01/2021 08:05:49 3
5 06/01/2021 08:05:50 4
6 06/01/2021 08:05:50 5
CodePudding user response:
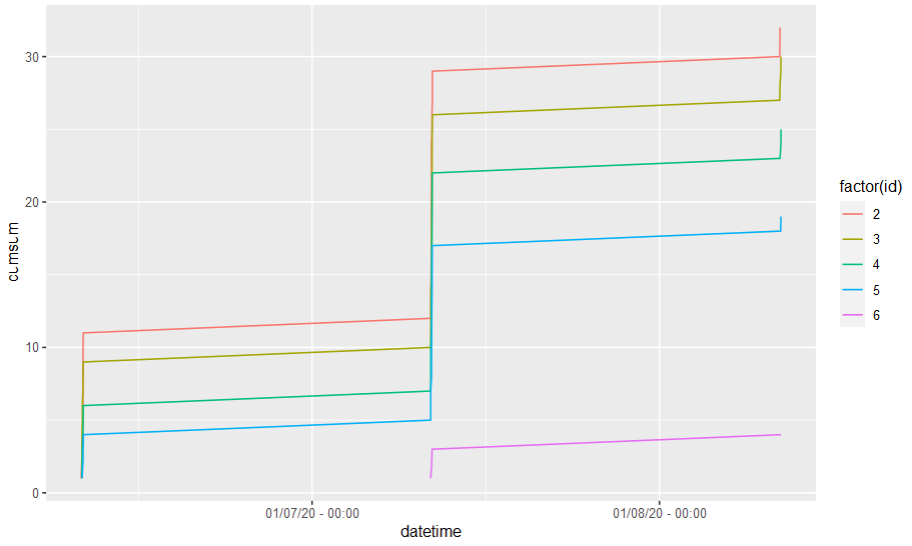
Do you mean something like that?
Using lubridate to convert your data in datetime object (easier to handle), then cumsum(!duplicated(datetime)) is used to count the number of (unique) visit by id. Then it is plotted with ggplot2.
The last line allows you to modify the x-axis breaks.
df %>%
mutate(datetime = as_datetime(paste(as.Date(date, "%d/%m/%y"), time))) %>%
group_by(id) %>%
mutate(cumsum = cumsum(!duplicated(datetime))) %>%
ggplot(aes(x = datetime, y = cumsum, color = factor(id), group = id))
geom_line()
scale_x_datetime(breaks = scales::date_breaks("1 day"), date_labels = "%D - %H:%M")
CodePudding user response:
A ggplot() plot solution considering data as a factor variable for specific and for all time steps.
Cumulative visits by id and date:
library(data.table)
dt=as.data.table(df)
dd<-dt[ , count := .N, by = .(id, date)]
dd$date<-as.factor(dd$date)
Create the plot:
ggplot(dd, aes(y=id, x=time, fill=count))
geom_tile()
scale_x_discrete(breaks = c("08:02:54","08:05:50", "08:07:34","08:10:02","08:13:25","08:16:32","08:19:44","08:23:52")) # remove this for all time-steps
facet_wrap(~date)
scale_fill_gradient(low="lightyellow", high="red")
labs(x="Time", y="Id", title="", fill="Number of visits")
theme_bw()
theme(plot.title = element_text(hjust = 0.5, face="bold", size=20, color="black"))
theme(axis.title.x = element_text(family="Times", face="bold", size=16, color="black"))
theme(axis.title.y = element_text(family="Times", face="bold", size=16, color="black"))
theme(axis.text.x = element_text( hjust = 1, face="bold", size=14, color="black", angle=90) )
theme(axis.text.y = element_text( hjust = 1, face="bold", size=14, color="black") )
theme(plot.title = element_text(hjust = 0.5))
theme(legend.title = element_text(family="Times", color = "black", size = 16,face="bold"),
legend.text = element_text(family="Times", color = "black", size = 14,face="bold"),
legend.position="right",
plot.title = element_text(hjust = 0.5))
theme(strip.text.x = element_text(size = 16, colour = "black",family="Times", face="bold"))
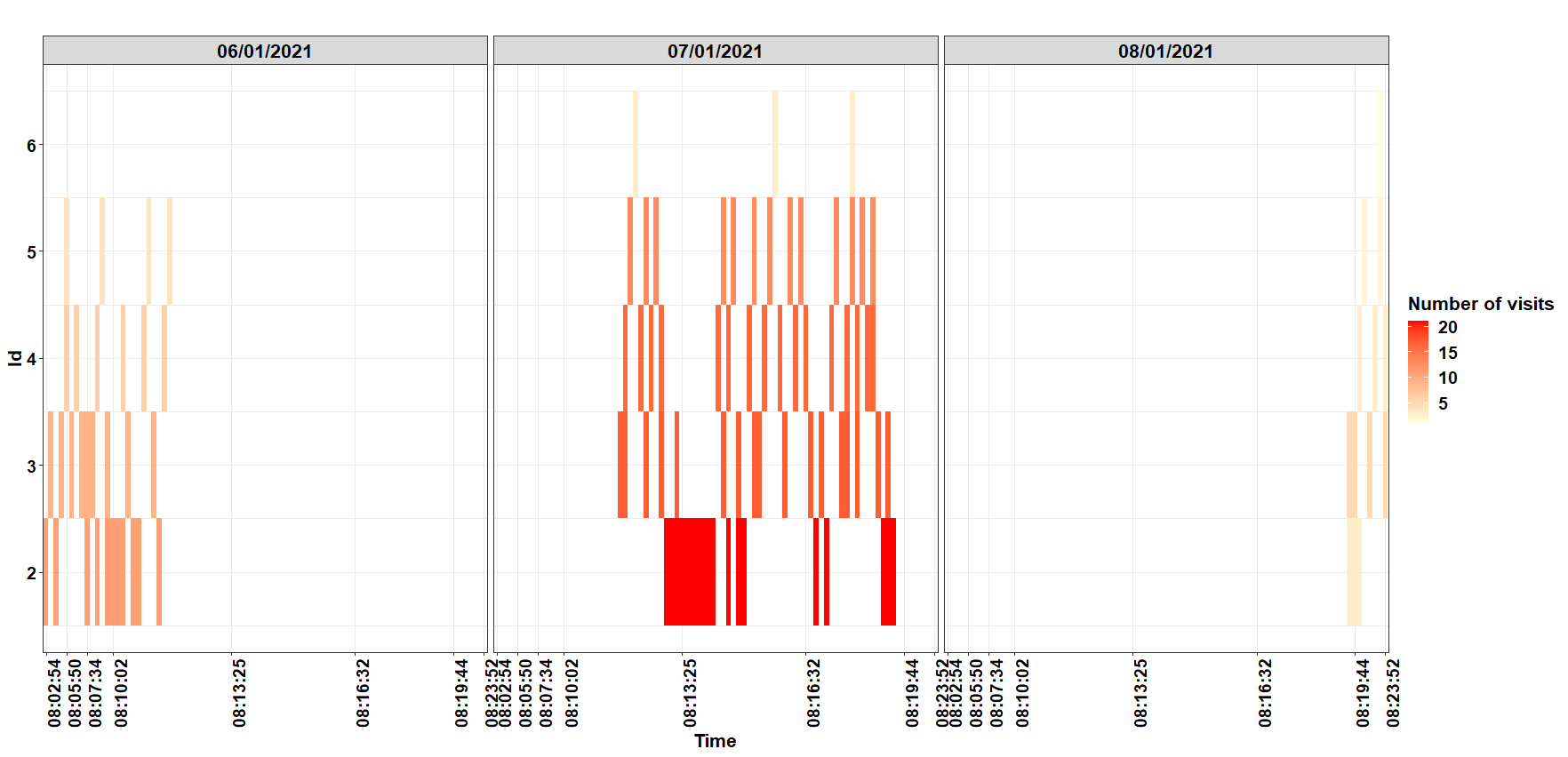
or without face_wrap()