My native language is not English, is Portuguese-BR and we have these accentuated characters (á, à, ã, õ, and so on).
So, my problem is, if I put one of these characters inside a string, and I try to iterate over each character inside it, I'm going to get that two characters are necessary to display "ã" on the screen.
Here's an image about me iterating over a string "(Não Informado)", which means: Uninformed. The string should have a length of 15 if we count each character one by one. But if we call strlen("(Não Informado)");, the result is 16.
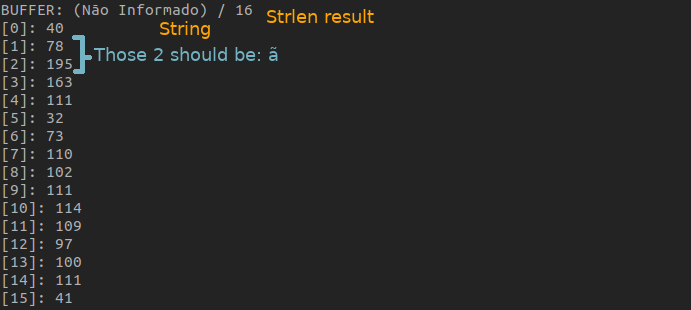
The code I used to print each character in this image is this one:
void print_buffer (const char * buffer) {
int size = strlen(buffer);
printf("BUFFER: %s / %i\n", buffer, size);
for (int i = 0; buffer[i] != '\0'; i) {
printf("[%i]: %i\n", i, (unsigned char) buffer[i]);
}
}
So, in graphical applications, a buffer could display "ãbc", and inside the raw string we wouldn't have 3 characters, but actually 4.
So here's my question, is there a way to know which characters inside a string are a composition of those special characters? Is there a rule to design and restrict this occurrence? Is it always a composition of 2 characters? Could a special character be composed of 3 or 4, for example?
Thanks
CodePudding user response:
is there a way to know which characters inside a string are a composition of those special characters?
Yes there is, to check if certain byte is part of a multibyte character you just need a bitwise operation (c & 0x80), an example:
#include <stdio.h>
int is_multibyte(int c)
{
return c & 0x80;
}
int main(void)
{
const char *str = "ãbc";
while (*str != 0)
{
printf(
"%c %s part of a multibyte\n",
*str, is_multibyte(*str) ? "is" : "is not"
);
str ;
}
return 0;
}
Output:
� is part of a multibyte
� is part of a multibyte
b is not part of a multibyte
c is not part of a multibyte
The string should have a length of 15 if we count each character one by one. But if we call strlen("(Não Informado)");, the result is 16.
It seems that you are intersted in the number of code points instead of the number of bytes, isn't it?
In this case you want to mask with (c & 0xc0) != 0x80:
#include <stdio.h>
size_t mylength(const char *str)
{
size_t len = 0;
while (*str != 0)
{
if ((*str & 0xc0) != 0x80)
{
len ;
}
str ;
}
return len;
}
int main(void)
{
const char *str = "ãbc";
printf("Length of \"%s\" = %zu\n", str, mylength(str));
return 0;
}
Output:
Length of "ãbc" = 3
Could a special character be composed of 3 or 4, for example?
Yes, of course, the euro sign € is an example (3 bytes), from this nice answer:
- Anything up to U 007F takes 1 byte: Basic Latin
- Then up to U 07FF it takes 2 bytes: Greek, Arabic, Cyrillic, Hebrew, etc
- Then up to U FFFF it takes 3 bytes: Chinese, Japanese, Korean, Devanagari, etc
- Beyond that it takes 4 bytes
Is there a rule to design and restrict this occurrence?
If you mean being able to treat all characters with the same width, C has specialised libraries for wide chars:
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main(void)
{
setlocale(LC_CTYPE, "");
wchar_t *str = L"ãbc";
while (*str != 0)
{
printf("%lc\n", *str);
str ;
}
return 0;
}
Output:
ã
b
c
To get the length you can use wcslen:
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main(void)
{
setlocale(LC_CTYPE, "");
wchar_t *str = L"ãbc";
printf("Length of \"%ls\" = %zu\n", str, wcslen(str));
return 0;
}
Output:
Length of "ãbc" = 3
But if with "restrict" you mean "avoid" those multibyte characters, you can transliterate from UTF8 to plain ASCII. If posix is an option take a look to iconv, you have an example here
El cañón de María vale 1000 €
is converted to
El canon de Maria vale 1000 EUR
and in your case
Não Informado
is converted to
Nao Informado