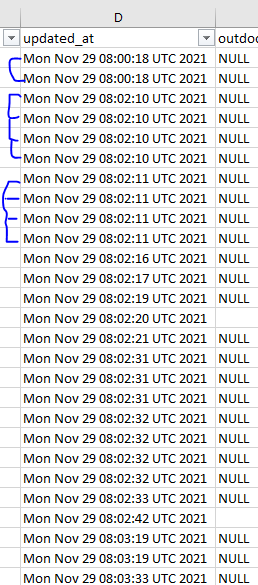
So I am doing some basic data processing. in the 'updated_at' column I am getting same value shown multiple times. How do I delete all of them except one? Hope the picture helps. let me know if you guys need more clarification.
df = df.set_index("updated_at")
new_df = df.where(~df.apply(pd.Series.duplicated, 1), "").reset_index()
I tried the code above but didnt works
[picture]
CodePudding user response:
import pandas as pd
df = pd.read_csv(filepath)
new_df = df.drop_duplicates(subset=['updated_at'])
new_df
CodePudding user response:
If you only need to consider the column updated_add you can use the code below. Alternative drop the subset argument if you need the elements in all your columns to be the same before a row is removed.
data.drop_duplicates(subset ="updated_at", inplace = True)
See the link below for more options https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html