We've been running into a very odd problem on our MySQL RDS instances with SELEC COUNT(*) commands and after three times of it happening and no luck finding a solution, I figure I'd ask here too.
The issue happens when (but not always) we do a SELECT COUNT(*) FROM on relatively large (1M rows) tables. The query, for some reason, spikes the server's CPU to 100% usage and takes way longer than it should.
We try to kill it via the KILL {threadId} command and the query will just switch on the processlist to status "killed" but nothing will happen.

I understand that running KILL on the thread only sets a flag that the query should be terminated - there's no immediate way to terminate it - but this is literally a SELECT COUNT(*) operation on a table to see how many rows are there. No WHERE clause, no JOINs, no need for the optimizer to create a virtual table and nothing to undo.
This has happened in production but also in our read-only replica mirror RDS, so it's not even a deadlock with other transactions [save for the replica process itself perhaps?] -- we couldn't find any notable deadlocks in the INNODB STATUS log either.
We can't figure out why a) such a simple command just up and murders the CPU b) why the thread just won't die.
We took the liberty last time to let the command keep running overnight to see if it was "just a matter of time and it will get killed when it's done processing whatever it is doing" but after 9 hours we had to reboot the server.
All for times this happened - thrice in Replica and unfortunately once in production - we had no choice but to reboot.
I can't tell if this is a MySQL bug [we're running 8.0.19] or what could be happening here... Any help on where to look or if this is a known issue would be greatly appreciated.
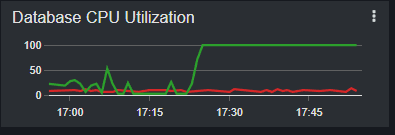
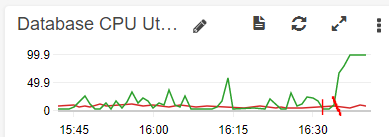
[[EDIT]] Ran the same command today to test for deadlocks. No deadlocks show up in the SHOW ENGINE INNODB STATUS results, but we noticed that the CPU only spikes once the KILL command is issued. The query itself only showed a moderate climb in Read IOPS but CPU usage was minimal - in fact it was actually falling when the SELECT was run, and only climbed once the KILL was issued.
[UPDATE]
@zedfoxus the table does have a primary key autoincrement field.
Here's the EXPLAIN of the original query:

And here's the explain of a select count on the id field:

[UPDATE 2] as recommended in comments by @zedfoxus, I tried running select count(*) from push_notification_async_queue use index (primary).
The query ran successfully in 6 minutes. As a test I decided to run the queyr and kill it preemptively, which caused the bad result to repeat.
Interesting note:
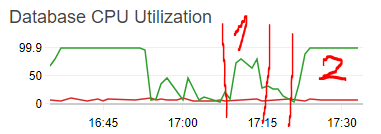
The select with use index(primary) ran in 6 minutes but the CPU usage only peaked at 70% and never really settled too high.
The killed query, however, immediately climbed to 100% and stayed there for 12 minutes, so it's not that it was just ignoring the kill flag and running normally....
CodePudding user response:
Why don't you just count a column instead.... Like select count(id).... Might work
CodePudding user response:
I think these solution can solve your problem. maybe all 3 solution or any one or two. 1 Select Data in the form Chunks. 2 Do Indexing. 3 if your are showing data on view then use pagination 4 if your are using laravel you should use db query because this this more fast then sql query.
CodePudding user response:
Quick answer
Doing
select count(*)
from push_notification_async_queue use index (primary)
or
select count(*)
from push_notification_async_queue use index (name-of-the-primary-key-index)
can yield faster results.
But why?
Primary key is auto incrementing. So, if you had IDs 1, 25 and 400 in the database, it is easier to count that in the index on IDs. Giving MySQL the hint to use the primary index (or explicitly giving the name of the primary index you have on IDs) will make MySQL read that index to answer the query.
How can we tell what MySQL was using without the hint?
EXPLAIN select count(*) from push_notification_async_queue
will tell us what index MySQL was choosing to answer the query.
Based on the results of explain, I could tell that MySQL thought it would get count(*) fastest from IX_push_notification_async_queue-sent_on field
id = 1
select_type = SIMPLE
table = push_notification_async_queue
key = IX_push_notification_async_queue-sent_on
key_len = 6
rows = 14870073
filtered = 100
extras = using index
However, IX_push_notification_async_queue-sent_on seems like a date. MySQL has to work lot harder to find count of rows based on an index that contained date/time. That made me think that using index hint will help.
Why would MySQL do silly things like this?
That's hard to tell. You can optimize or analyze table and see if that helps. It can take a long time, so I recommend you take a backup from your production system, restore on your local computer or a test system and try it there. https://dev.mysql.com/doc/refman/8.0/en/table-maintenance-statements.html gives you details about those commands.
On a table that is written to, deleted from, or read from heavily, statistics could take time to build and that can cause MySQL to choose an index that it feels satisfies the query best. There's some good discussion in this thread: MySQL uses incorrect index. Why?