I am trying to create some random samples (of a given size) from a static dataframe. The goal is to create multiple columns for each sample (and each sample drawn is the same size). I'm expecting to see multiple columns of the same length (i.e. sample size) in the fully sampled dataframe, but maybe append isn't the right way to go. Here is the code:
# create sample dataframe
target_df = pd.DataFrame(np.arange(1000))
target_df.columns=['pl']
# create the sampler:
sample_num = 5
sample_len = 10
df_max_row = len(target_df) - sample_len
for i in range(sample_num):
rndm_start = np.random.choice(df_max_row, 1)[0]
rndm_end = rndm_start sample_len
slicer = target_df.iloc[rndm_start:rndm_end]['pl']
sampled_df = sampled_df.append(slicer, ignore_index=True)
sampled_df = sampled_df.T
The output of this is shown in the pic below - The red line shows the index I want remove.
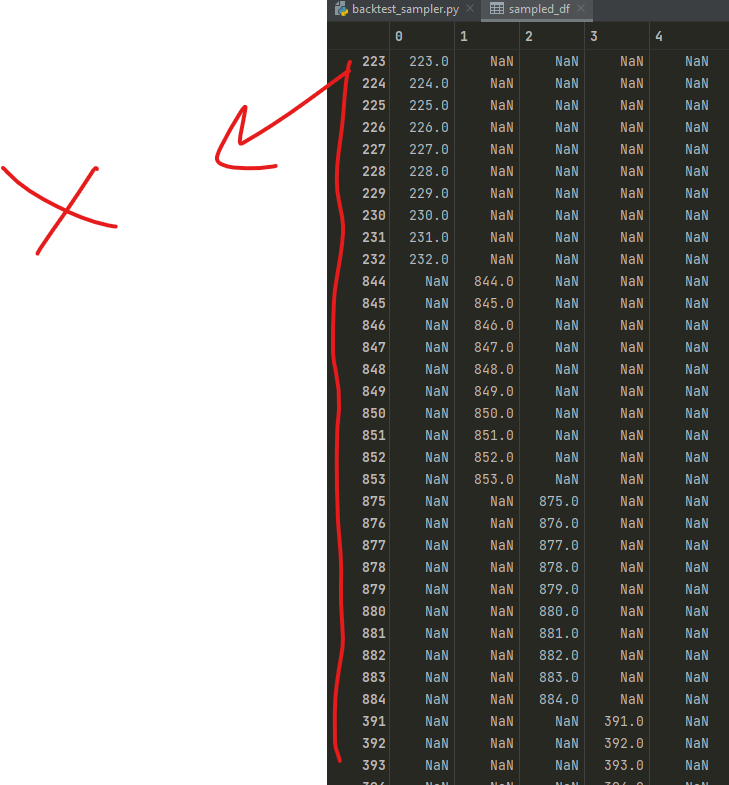
The desired output is shown below that. How do I make this happen?
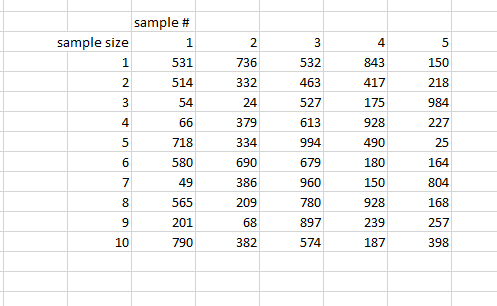
Thanks!
CodePudding user response:
I would create new column using
sampled_df[i] = slicer.reset_index(drop=True)
Eventually I would use str(i) for column name because later it is simpler to select column using string than number
import pandas as pd
import random
target_df = pd.DataFrame({'pl': range(1000)})
# create the sampler:
sample_num = 5
sample_len = 10
df_max_row = len(target_df) - sample_len
sampled_df = pd.DataFrame()
for i in range(1, sample_num 1):
start = random.randint(0, df_max_row)
end = start sample_len
slicer = target_df[start:end]['pl']
sampled_df[str(i)] = slicer.reset_index(drop=True)
sampled_df.index = 1
print(sampled_df)
Result:
1 2 3 4 5
1 735 396 646 534 769
2 736 397 647 535 770
3 737 398 648 536 771
4 738 399 649 537 772
5 739 400 650 538 773
6 740 401 651 539 774
7 741 402 652 540 775
8 742 403 653 541 776
9 743 404 654 542 777
10 744 405 655 543 778
But to create really random values then I would first shuffle values
np.random.shuffle(target_df['pl'])
and then I don't have to use random to select start
shuffle changes original column so it can't assign to new variable.
It doesn't repeat values in samples.
import pandas as pd
#import numpy as np
import random
target_df = pd.DataFrame({'pl': range(1000)})
# create the sampler:
sample_num = 5
sample_len = 10
sampled_df = pd.DataFrame()
#np.random.shuffle(target_df['pl'])
random.shuffle(target_df['pl'])
for i in range(1, sample_num 1):
start = i * sample_len
end = start sample_len
slicer = target_df[start:end]['pl']
sampled_df[str(i)] = slicer.reset_index(drop=True)
sampled_df.index = 1
print(sampled_df)
Result:
1 2 3 4 5
1 638 331 171 989 170
2 22 643 47 136 764
3 969 455 211 763 194
4 859 384 174 552 566
5 221 829 62 926 414
6 4 895 951 967 381
7 758 688 594 876 873
8 757 691 825 693 707
9 235 353 34 699 121
10 447 81 36 682 251
If values can repeat then you could use
sampled_df[str(i)] = target_df['pl'].sample(n=sample_len, ignore_index=True)
import pandas as pd
target_df = pd.DataFrame({'pl': range(1000)})
# create the sampler:
sample_num = 5
sample_len = 10
sampled_df = pd.DataFrame()
for i in range(1, sample_num 1):
sampled_df[str(i)] = target_df['pl'].sample(n=sample_len, ignore_index=True)
sampled_df.index = 1
print(sampled_df)
EDIT
You may also get shuffled values as numpy array and use reshape - and later convert back to DataFrame with many columns. And later you can get some columns.
import pandas as pd
import random
target_df = pd.DataFrame({'pl': range(1000)})
# create the sampler:
sample_num = 5
sample_len = 10
random.shuffle(target_df['pl'])
sampled_df = pd.DataFrame(target_df['pl'].values.reshape([sample_len,-1]))
sampled_df = sampled_df.iloc[:, 0:sample_num]
sampled_df.index = 1
print(sampled_df)