I would like to save a multi-header DataFrame as Excel file. Following is the sample code:
import pandas as pd
import numpy as np
header = pd.MultiIndex.from_product([['location1','location2'],
['S1','S2','S3']],
names=['loc','S'])
df = pd.DataFrame(np.random.randn(5, 6),
index=['a','b','c','d','e'],
columns=header)
df.to_excel('result.xlsx')
There are two issues in the excel file as can be seen below:
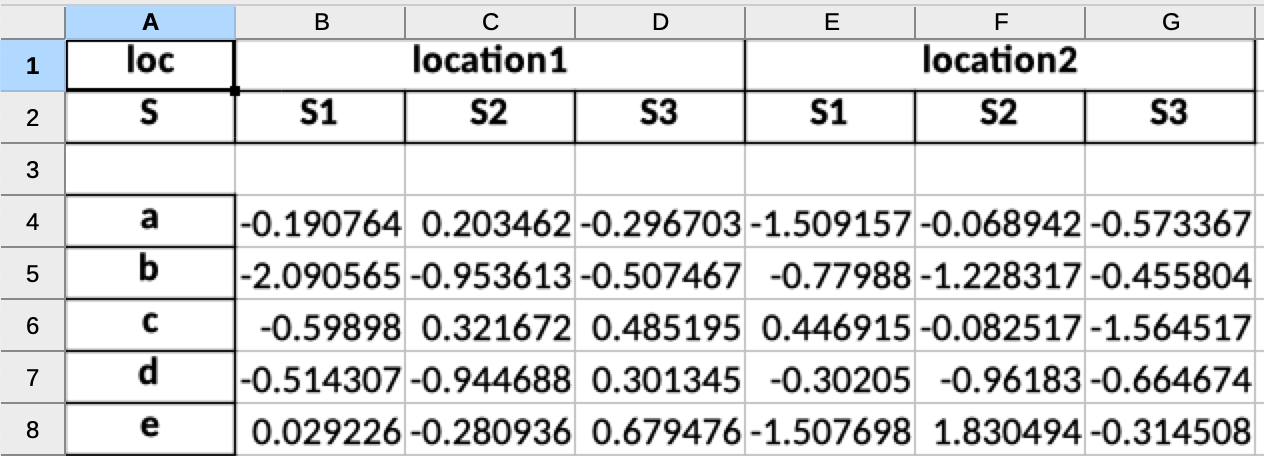
Issue 1:
There is an empty row under headers. Please let me know how to avoid Pandas to write / insert an empty row in the Excel file.
Issue 2:
I want to save DataFrame without index. However, when I set index=False, I get the following error:
df.to_excel('result.xlsx', index=False)
Error:
NotImplementedError: Writing to Excel with MultiIndex columns and no index ('index'=False) is not yet implemented.
CodePudding user response:
You can create 2 Dataframes - only headers and with default header and write both to same sheet with startrow parameter:
header = df.columns.to_frame(index=False)
header.loc[header['loc'].duplicated(), 'loc'] = ''
header = header.T
print (header)
0 1 2 3 4 5
loc location1 location2
S S1 S2 S3 S1 S2 S3
df1 = df.set_axis(range(len(df.columns)), axis=1)
print (df1)
0 1 2 3 4 5
a -1.603958 1.067986 0.474493 -0.352657 -2.198830 -2.028590
b -0.989817 -0.621200 0.010686 -0.248616 1.121244 0.727779
c -0.851071 -0.593429 -1.398475 0.281235 -0.261898 -0.568850
d 1.414492 -1.309289 -0.581249 -0.718679 -0.307876 0.535318
e -2.108857 -1.870788 1.079796 0.478511 0.613011 -0.441136
with pd.ExcelWriter('output.xlsx') as writer:
header.to_excel(writer, sheet_name='Sheet_name_1', header=False, index=False)
df1.to_excel(writer, sheet_name='Sheet_name_1', header=False, index=False, startrow=2)