I'm working on a binary classification task with Pytorch and my model is failing to learn, I can't figure out if it is a problem with the model or with the data.
Here is my model:
from torch import nn
class RNN(nn.Module):
def __init__(self, input_dim):
super(RNN, self).__init__()
self.rnn = nn.RNN(input_size=input_dim, hidden_size=64,
num_layers=2,
batch_first=True, bidirectional=True)
self.norm = nn.BatchNorm1d(128)
self.rnn2 = nn.RNN(input_size=128, hidden_size=64,
num_layers=2,
batch_first=True, bidirectional=False)
self.drop = nn.Dropout(0.5)
self.fc7 = nn.Linear(64, 2)
self.sigmoid2 = nn.Softmax(dim=2)
def forward(self, x):
out, h_n = self.rnn(x)
out = out.permute(0, 2, 1)
out = self.norm(out)
out = out.permute(0, 2, 1)
out, h_n = self.rnn2(out)
out = self.drop(out)
out = self.fc7(out)
out = self.sigmoid2(out)
return out.squeeze()
The model consists in two RNN layers, with a BatchNorm in between, then a Dropout and the last layer, I use Softmax function with two classes instead of Sigmoid for evaluation purposes.
Then I create and train the model:
model = RNN(2476)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_function = nn.CrossEntropyLoss()
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
model.train()
EPOCHS = 25
BATCH_SIZE = 64
epoch_loss = []
for ii in range(EPOCHS):
for i in range(1, X_train.size()[0]//BATCH_SIZE 1):
x_train = X_train[(i-1)*BATCH_SIZE:i*BATCH_SIZE]
labels = y_train[(i-1)*BATCH_SIZE:i*BATCH_SIZE]
optimizer.zero_grad()
y_pred = model(x_train)
y_pred = y_pred.round()
single_loss = loss_function(y_pred, labels.long().squeeze())
single_loss.backward()
optimizer.step()
lr_scheduler.step()
print(f"\rBatch {i}/{X_train.size()[0]//BATCH_SIZE 1} Trained: {i*BATCH_SIZE}/{X_train.size()[0]} Loss: {single_loss.item():10.8f} Step: {lr_scheduler.get_lr()}", end="")
epoch_loss.append(single_loss.item())
print(f'\nepoch: {ii:3} loss: {single_loss.item():10.8f}')
This is the output when training the model:
Batch 353/354 Trained: 22592/22644 Loss: 0.86013699 Step: [1.0000000000000007e-21]
epoch: 0 loss: 0.86013699
Batch 353/354 Trained: 22592/22644 Loss: 0.81326193 Step: [1.0000000000000014e-33]
epoch: 1 loss: 0.81326193
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000022e-45]
epoch: 2 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.92263710 Step: [1.0000000000000026e-57]
epoch: 3 loss: 0.92263710
Batch 353/354 Trained: 22592/22644 Loss: 0.90701210 Step: [1.0000000000000034e-68]
epoch: 4 loss: 0.90701210
Batch 353/354 Trained: 22592/22644 Loss: 0.92263699 Step: [1.0000000000000039e-80]
epoch: 5 loss: 0.92263699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000044e-92]
epoch: 6 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.81326193 Step: [1.000000000000005e-104]]
epoch: 7 loss: 0.81326193
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000055e-115]
epoch: 8 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000062e-127]
epoch: 9 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.81326199 Step: [1.0000000000000067e-139]
epoch: 10 loss: 0.81326199
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000072e-151]
epoch: 11 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.89138699 Step: [1.0000000000000076e-162]
epoch: 12 loss: 0.89138699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888699 Step: [1.000000000000008e-174]]
epoch: 13 loss: 0.82888699
Batch 353/354 Trained: 22592/22644 Loss: 0.82888687 Step: [1.0000000000000089e-186]
epoch: 14 loss: 0.82888687
Batch 353/354 Trained: 22592/22644 Loss: 0.82888693 Step: [1.0000000000000096e-198]
epoch: 15 loss: 0.82888693
Batch 353/354 Trained: 22592/22644 Loss: 0.84451199 Step: [1.0000000000000103e-210]
epoch: 16 loss: 0.84451199
Batch 353/354 Trained: 22592/22644 Loss: 0.96951205 Step: [1.0000000000000111e-221]
epoch: 17 loss: 0.96951205
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.0000000000000117e-233]
epoch: 18 loss: 0.87576205
Batch 353/354 Trained: 22592/22644 Loss: 0.89138705 Step: [1.0000000000000125e-245]
epoch: 19 loss: 0.89138705
Batch 353/354 Trained: 22592/22644 Loss: 0.79763699 Step: [1.0000000000000133e-257]
epoch: 20 loss: 0.79763699
Batch 353/354 Trained: 22592/22644 Loss: 0.84451199 Step: [1.0000000000000138e-268]
epoch: 21 loss: 0.84451199
Batch 353/354 Trained: 22592/22644 Loss: 0.84451205 Step: [1.0000000000000146e-280]
epoch: 22 loss: 0.84451205
Batch 353/354 Trained: 22592/22644 Loss: 0.79763693 Step: [1.0000000000000153e-292]
epoch: 23 loss: 0.79763693
Batch 353/354 Trained: 22592/22644 Loss: 0.87576205 Step: [1.000000000000016e-304]]
epoch: 24 loss: 0.87576205
And this is the loss per epoch:
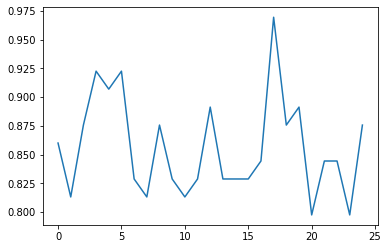
For the data, each of the features in the input data have a dimension of (2474,), and the targets have 1 dimension (either [1] or [0]) , then I add the sequence length dimension (1) to the input data for the RNN layers :
X_train.size(), X_test.size(), y_train.size(), y_test.size()
(torch.Size([22644, 1, 2474]),
torch.Size([5661, 1, 2474]),
torch.Size([22644, 1]),
torch.Size([5661, 1]))
Distribution of the target classes:
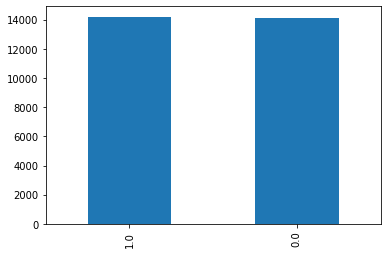
I can't figure out why my model is not learning, the classes are balanced and I haven't notified anything wrong with the data. Any suggestions?
CodePudding user response:
This is not a direct solution to your problem, but what was the process that led to this architecture? I've found it helpful to build up complexity iteratively if only to make identifying issues more trivial (what did I add just before the issue arose?).
To save time on constructing your RNN iteratively, you can try single-batch training by which you construct a network that can overfit a single training batch. If your network can overfit a single training batch, it should be complex enough to learn the features in the training data.
Once you have an architecture that can easily overfit a single training batch, you can then train with the entire training set and explore additional strategies to account for overfitting through regularization.
Your model doesn't seem overly complex but this may mean starting with a single rnn layer and a single linear layer to see if your loss will budge on a single batch.