I am very new to this so be please nice!
My dataset has 3 columns - Col A (chr, 'X' and 'Y'), Col B (chr, 'red', 'blue' 'yellow'), Col C (numeric).
Col_A <- c('X', 'X', 'X', 'Y', 'Y', 'X', 'Y', 'X')
Col_B <- c('red', 'yellow', 'blue', 'blue', 'yellow', 'red', 'blue', 'red')
Col_C <- c(12, 22, 13, 14, 25, 17, 11, 10)
dataset <- as.data.frame(cbind(Col_A, Col_B, Col_C))
How can I create a summary table in R that's like
tbl_summary(dataset, by = 'Col_A')
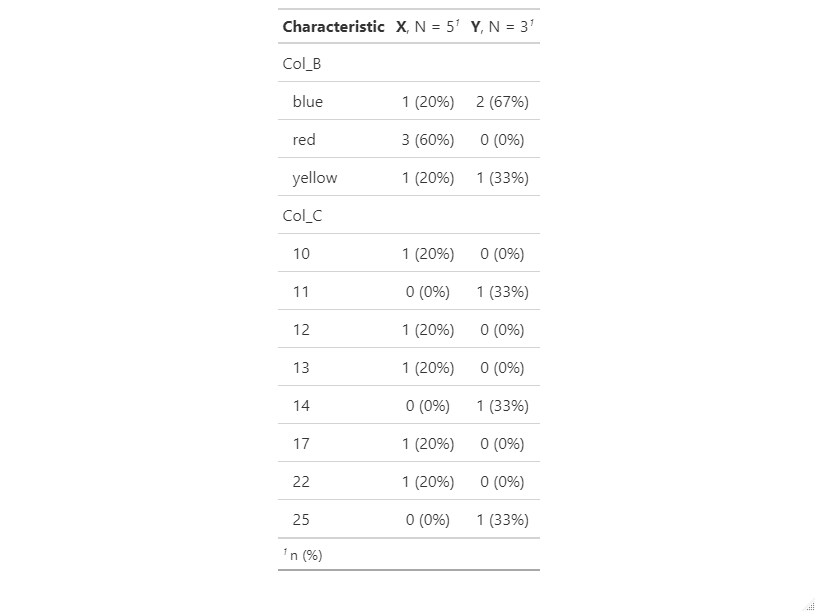
but gives the mean values of Col C for every subgroup in Col B?
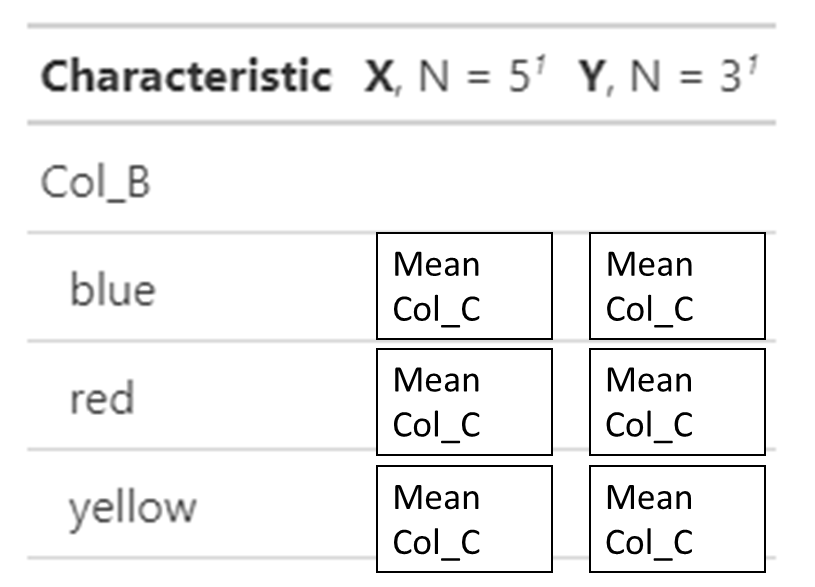
Right now the code gives me counts for Col B and then the mean value of Col C for 'X' and 'Y'.
Does any of that even make sense?!
CodePudding user response:
Is this what you are looking for? Updated with base R and dplyr options.
# simpler way to create a data.frame and preserve variable types.
Col_A <- c('X', 'X', 'X', 'Y', 'Y', 'X', 'Y', 'X')
Col_B <- c('red', 'yellow', 'blue', 'blue', 'yellow', 'red', 'blue', 'red')
Col_C <- c(12, 22, 13, 14, 25, 17, 11, 10)
dataset <- data.frame(Col_A, Col_B, Col_C)
#Using base R `aggregate`
aggregate(Col_C ~ Col_A Col_B, data = dataset, mean)
# with `dplyr`
library(dplyr, warn.conflicts = FALSE)
dataset <-
dataset %>%
group_by(Col_A, Col_B) %>%
summarise(mean = mean(Col_C, na.rm = TRUE))
dataset
#> # A tibble: 5 x 3
#> # Groups: Col_A [2]
#> Col_A Col_B mean
#> <chr> <chr> <dbl>
#> 1 X blue 13
#> 2 X red 13
#> 3 X yellow 22
#> 4 Y blue 12.5
#> 5 Y yellow 25
# and as a `gt` table
library(gt)
gt(dataset)
Created on 2021-12-23 by the reprex package (v2.0.1)
CodePudding user response:
Use the data.table structure and it's by parameter
library(data.table)
dataset <- data.table(Col_A, Col_B, Col_C)
dataset[, mean(Col_C), keyby=Col_B]