I have a dictionary in python, each key has a value of nested lists, like following:
test = {'x':[[1,2,3],[4,5,6]], 'y':[[1,2,3],[4,5,6]]}
and I want to convert the dictionary key into dataframe column names in pandas and the nested lists into series of list, like following:
| 'x' | 'y' |
|---|---|
| [1,2,3] | [1,2,3] |
| [4,5,6] | [4,5,6] |
Is there any way to do so?
CodePudding user response:
Try:
import pandas as pd
df = pd.DataFrame(test)
print(df)
Here is the output in my ide:
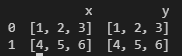
If you want to save the Dataframe into a csv file, you should:
output_name = 'myfile.csv'
df.to_csv(output_name)
This will create a csv, universal name for excel like files into your working directory. You can check it's existence with:
import os
os.listdir()
CodePudding user response:
Just convert it to a dataframe, this code returns what you need.
import pandas as pd
import numpy as np
test = {'x':[[1,2,3],[4,5,6]], 'y':[[1,2,3],[4,5,6]]}
df = pd.DataFrame(test)
This returns the following:
x y
0 [1, 2, 3] [1, 2, 3]
1 [4, 5, 6] [4, 5, 6]
You can then convert it to a csv file and set the index=False to remove the row numbers(0 and 1 in this case):
df.to_csv('df.csv', index=False)
That should give you the output as follows:
x y
[1, 2, 3] [1, 2, 3]
[4, 5, 6] [4, 5, 6]
CodePudding user response:
Try this :
pd.DataFrame(columns =test.keys() ,data = test.values())
It resolves the Value error thrown by @girolamo's answer .
For
test = {'x':[[1,2,3],[4,5,6]], 'y':[[1,2,3]]}
It gives output :
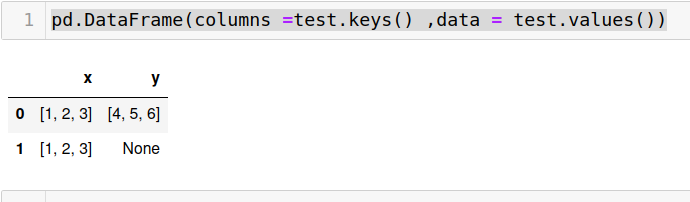
That is if len of x and y are different it returns None