I have a dataset of tweets made in this way:
mydata <- read.csv(header=TRUE, text='"tweet","Topic","created_at"
"text1","topic1","2020-08-13"
"text2","topic2","2020-08-11"
"text3","topic2","2020-08-11"
"text4","topic2","2020-08-10"
"text5","topic1","2020-08-13"
"text6","topic1","2020-08-14"
"text7","topic1","2020-08-15"')
I want to plot the occurrence of each topic over time day by day (for example, if on 2020-08-11 there have been 5 tweets belonging to topic 1 and 2 tweets belonging to topic 2, the value of topic 1 for that day will be 5 and for topic 2 will be 2, and so on), and I'm trying to do it with this code:
mydata%>%
mutate(created_at = lubridate::ymd_hms(created_at),
date = as.Date(created_at)) %>%
count(date, Topic) %>%
ggplot(aes(date, n, color = Topic)) geom_line()
labs(y="n° tweets")
But I'm receiving this error:
Error in seq.int(0, to0 - from, by) : 'to' must be a finite number
What can I do?
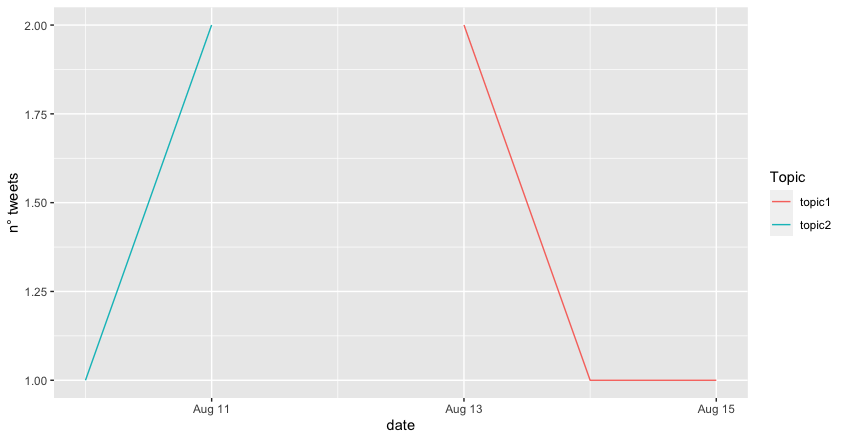
My goal is a result like this:
CodePudding user response:
created_at does not have the proper format for lubridate::ymd_hms() which creates NA-values in your dataset. You can simply remove it and use as.Date() and your code does what you want:
mydata %>%
mutate(date = as.Date(created_at)) %>%
count(date, Topic) %>%
ggplot(aes(date, n, color = Topic)) geom_line()
labs(y="n° tweets")