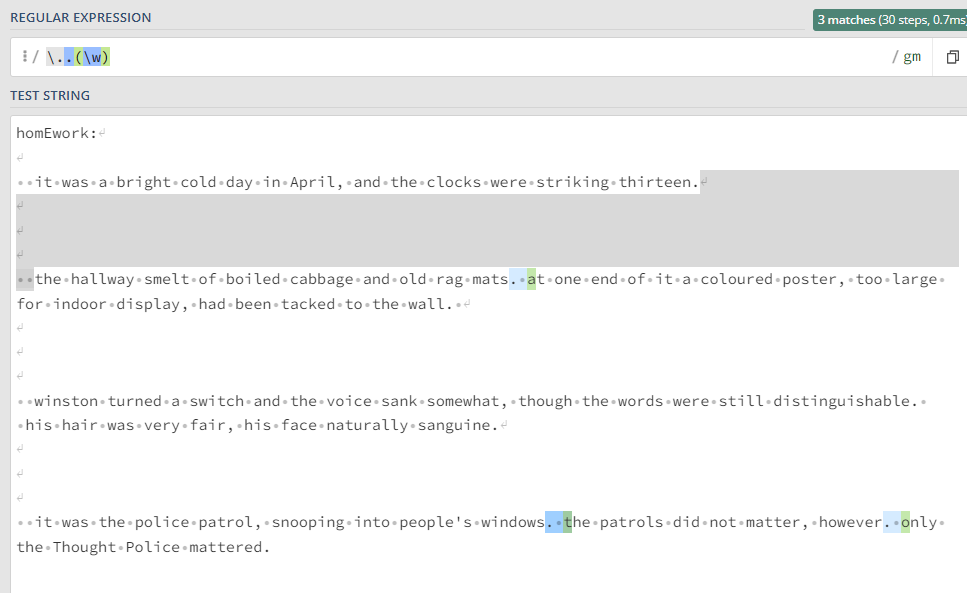
I am trying to extract first word character after the dot with this regex:
\..(\w)
But it is not working with new lines and spaces.
homEwork:
it was a bright cold day in April, and the clocks were striking thirteen.
the hallway smelt of boiled cabbage and old rag mats. at one end of it a coloured poster, too large for indoor display, had been tacked to the wall.
winston turned a switch and the voice sank somewhat, though the words were still distinguishable. his hair was very fair, his face naturally sanguine.
it was the police patrol, snooping into people's windows. the patrols did not matter, however. only the Thought Police mattered.
CodePudding user response:
You can use \.\s*(\w )
>>> re.findall(r'\.\s*(\w)', text)
['the', 'at', 'winston', 'his', 'it', 'the', 'only']
\.: literal dot\s*: 0 or more whitespace(\w ): 1 or more [a-zA-Z0-9_]. Parenthesis are for capture group
CodePudding user response:
You can do this with string methods
import re
word = """ it was a bright cold day in April, and the clocks were striking thirteen.
the hallway smelt of boiled cabbage and old rag mats. at one end of it a coloured poster, too large for indoor display, had been tacked to the wall.
winston turned a switch and the voice sank somewhat, though the words were still distinguishable. his hair was very fair, his face naturally sanguine.
it was the police patrol, snooping into people's windows. the patrols did not matter, however. only the Thought Police mattered.```
[1]: https://i.stack.imgur.com/vCGA8.png"""
#remove new lines
word = word.replace('\n','')
#remove space
word = re.sub('\. ', '.', word)
#position of .
pos =word.find('.')
#next character after .
if (pos 1) < len(word):
word[pos 1]