I've created a dataframe using random values using the following code:
values = random(5)
values_1= random(5)
col1= list(values/ values .sum())
col2= list(values_1)
df = pd.DataFrame({'col1':col1, 'col2':col2})
df.sort_values(by=['col2','col1'],ascending=[False,False]).reset_index(inplace=True)
The dataframe created in my case looks like this:
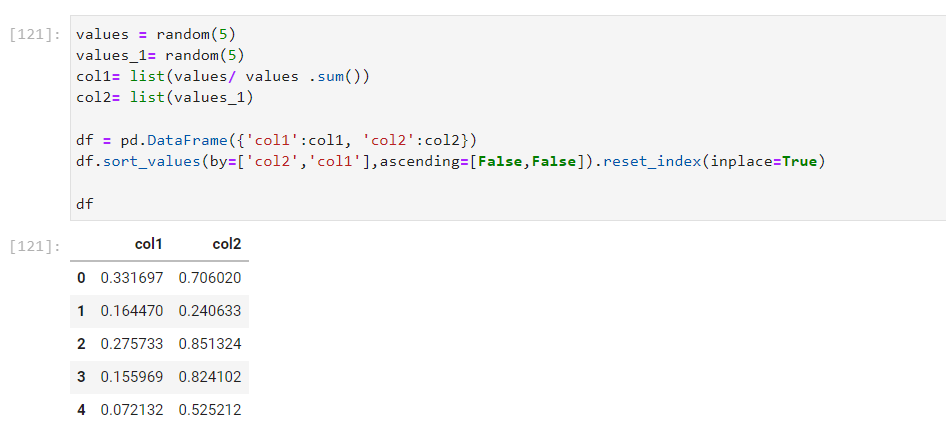
As you can see, the dataframe is not sorted in descending order by 'col2'. What I want to achieve is that it first sorts by 'col2' and if any 2 rows have same values for 'col2', then it should sort by 'col1' as well. Any suggestions? Any help would be appreciated.
CodePudding user response:
Your solution almost working well, but if use inplace in reset_index it is not reused in sort_values.
Possible solution is add ignore_index=True, so reset_index is not necessary.
np.random.seed(2022)
df = pd.DataFrame({'col1':np.random.random(5), 'col2':np.random.random(5)})
df = df.sort_values(by=['col2','col1'],ascending=False, ignore_index=True)
print (df)
col1 col2
0 0.499058 0.897657
1 0.049974 0.896963
2 0.685408 0.721135
3 0.113384 0.647452
4 0.009359 0.486988
Or if want use inplace add it only to sort_values and add also ignore_index=True:
df.sort_values(by=['col2','col1'],ascending=False, ignore_index=True,inplace=True)
print (df)
col1 col2
0 0.499058 0.897657
1 0.049974 0.896963
2 0.685408 0.721135
3 0.113384 0.647452
4 0.009359 0.486988
CodePudding user response:
Your logic is correct but you've missed an inplace=True inside sort_values. Due to this, the sorting does not actually take place in your dataframe. Replace it with this:
df.sort_values(by=['col2','col1'],ascending=[False,False],inplace=True)
df.reset_index(inplace=True,drop=True)
CodePudding user response:
You want to also do the sort inplace=True, not only the reset_index()