I have a DataFrame that looks like this (code to produce this at end):
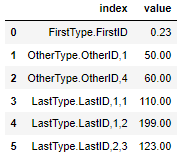
... and I want to basically split up the index column, to get to this:
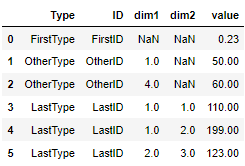
There could be a variable number of comma-separated numbers after each Type.ID. I've written a function that does the splitting up for individual strings, but I don't know how to apply it to a column (I looked at apply).
Thank you for your help! Code to set up input DataFrame:
pd.DataFrame({
'index': pd.Series(['FirstType.FirstID', 'OtherType.OtherID,1','OtherType.OtherID,4','LastType.LastID,1,1', 'LastType.LastID,1,2', 'LastType.LastID,2,3'],dtype='object',index=pd.RangeIndex(start=0, stop=6, step=1)),
'value': pd.Series([0.23, 50, 60, 110.0, 199.0, 123.0],dtype='float64',index=pd.RangeIndex(start=0, stop=6, step=1)),
}, index=pd.RangeIndex(start=0, stop=6, step=1))
Code to split up index values:
def get_header_properties(header):
pf_type = re.match(".*?(?=\.)", header).group()
pf_id = re.search(f"(?<={pf_type}\.).*?(?=(,|$))", header).group()
pf_coords = re.search(f"(?<={pf_id}).*", header).group()
return pf_type, pf_id, pf_coords.split(",")[1:]
get_header_properties("EquityPriceVol.EQ_NDASE_104277,0.625,0.0833333333333333")
CodePudding user response:
You could slightly change the function and use it in a list comprehension; then assign the nested list to columns:
def get_header_properties(header):
pf_type = re.match(".*?(?=\.)", header).group()
pf_id = re.search(f"(?<={pf_type}\.).*?(?=(,|$))", header).group()
pf_coords = re.search(f"(?<={pf_id}).*", header).group()
coords = pf_coords.split(",")[1:]
return [pf_type, pf_id] coords ([np.nan]*(2-len(coords)) if len(coords)<2 else [])
df[['Type','ID','dim1','dim2']] = [get_header_properties(i) for i in df['index']]
out = df.drop(columns='index')[['Type','ID','dim1','dim2','value']]
That said, instead of the function, it seems it's simpler and more efficient to use str.split once on "index" column and join it to df:
df = (df['index'].str.split('[.,]', expand=True)
.fillna(np.nan)
.rename(columns={i: col for i,col in enumerate(['Type','ID','dim1','dim2'])})
.join(df[['value']]))
Output:
Type ID dim1 dim2 value
0 FirstType FirstID NaN NaN 0.23
1 OtherType OtherID 1 NaN 50.00
2 OtherType OtherID 4 NaN 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00
CodePudding user response:
You can directly expand a regex over the problematic column!
>>> df["index"].str.extract(r"([^\.] )\.([^,] )(?:,(\d ))?(?:,(\d ))?")
0 1 2 3
0 FirstType FirstID NaN NaN
1 OtherType OtherID 1 NaN
2 OtherType OtherID 4 NaN
3 LastType LastID 1 1
4 LastType LastID 1 2
5 LastType LastID 2 3
Joining the value column to the end (opportunity for other columns here too)
df_idx = df["index"].str.extract(r"([^\.] )\.([^,] )(?:,(\d ))?(?:,(\d ))?")
df = df_idx.join(df[["value"]])
df = df.rename({0: "Type", 1: "ID", 2: "dim1", 3: "dim2"}, axis=1)
>>> df
Type ID dim1 dim2 value
0 FirstType FirstID NaN NaN 0.23
1 OtherType OtherID 1 NaN 50.00
2 OtherType OtherID 4 NaN 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00
CodePudding user response:
IMO, the simplest is just to split:
df2 = df['index'].str.split('[,.]', expand=True)
df2.columns = ['Type', 'ID', 'dim1', 'dim2']
df2 = df2.join(df['value'])
NB. The regex relies here on the dot/comma separators, but you can adapt if needed
Output:
Type ID dim1 dim2 value
0 FirstType FirstID None None 0.23
1 OtherType OtherID 1 None 50.00
2 OtherType OtherID 4 None 60.00
3 LastType LastID 1 1 110.00
4 LastType LastID 1 2 199.00
5 LastType LastID 2 3 123.00