I am new to python and need to have some database management. I have a large dataset in CSV and the column name repeats after a certain column. I need to copy that column set below the end of rows of the first set. As shown in the image below, I want to cut and paste the dataset for each ID { 03]01]17, 03]01]16, 03]01]15 and so on...I have attached here the sample data and required format. 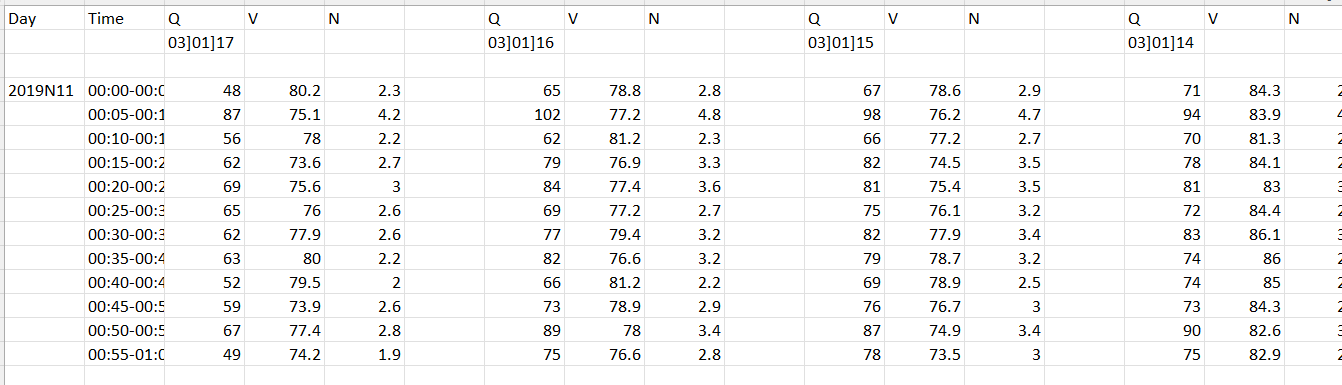
,Day,Time,Q,V,N,Unnamed: 5,Q.1,V.1,N.1,Unnamed: 9,Q.2,V.2,N.2,Unnamed: 13,Q.3,V.3,N.3
0,,,03]01]17,,,,03]01]16,,,,03]01]15,,,,03]01]14,,
1,,,,,,,,,,,,,,,,,
2,2019N11,00:00-00:05,48,80.2,2.3,,65,78.8,2.8,,67,78.6,2.9, ,71,84.3,2.6
3,,00:05-00:10,87,75.1,4.2,,102,77.2,4.8,,98,76.2,4.7, ,94,83.9,4.4
4,,00:10-00:15,56,78.0,2.2,,62,81.2,2.3,,66,77.2,2.7, ,70,81.3,2.6
5,,00:15-00:20,62,73.6,2.7,,79,76.9,3.3,,82,74.5,3.5, ,78,84.1,2.8
6,,00:20-00:25,69,75.6,3.0,,84,77.4,3.6,,81,75.4,3.5, ,81,83.0,3.2
7,,00:25-00:30,65,76.0,2.6,,69,77.2,2.7,,75,76.1,3.2, ,72,84.4,2.7
8,,00:30-00:35,62,77.9,2.6,,77,79.4,3.2,,82,77.9,3.4, ,83,86.1,3.1
9,,00:35-00:40,63,80.0,2.2,,82,76.6,3.2,,79,78.7,3.2, ,74,86.0,2.6
10,,00:40-00:45,52,79.5,2.0,,66,81.2,2.2,,69,78.9,2.5, ,74,85.0,2.6
11,,00:45-00:50,59,73.9,2.6,,73,78.9,2.9,,76,76.7,3.0, ,73,84.3,2.6
12,,00:50-00:55,67,77.4,2.8,,89,78.0,3.4,,87,74.9,3.4, ,90,82.6,3.1
13,,00:55-01:00,49,74.2,1.9,,75,76.6,2.8,,78,73.5,3.0, ,75,82.9,2.6
dfsample = pd.read_clipboard(sep=',')
dfsample
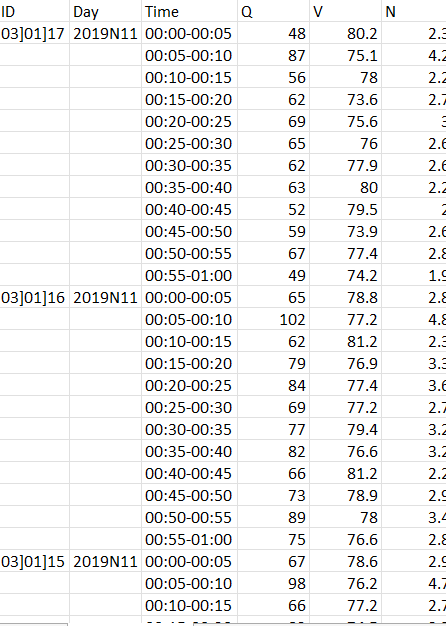
##Required_format
,ID,Day,Time,Q,V,N
0,03]01]17,2019N11,00:00-00:05,48,80.2,2.3
1,,,00:05-00:10,87,75.1,4.2
2,,,00:10-00:15,56,78.0,2.2
3,,,00:15-00:20,62,73.6,2.7
4,,,00:20-00:25,69,75.6,3.0
5,,,00:25-00:30,65,76.0,2.6
6,,,00:30-00:35,62,77.9,2.6
7,,,00:35-00:40,63,80.0,2.2
8,,,00:40-00:45,52,79.5,2.0
9,,,00:45-00:50,59,73.9,2.6
10,,,00:50-00:55,67,77.4,2.8
11,,,00:55-01:00,49,74.2,1.9
12,03]01]16,2019N11,00:00-00:05,65,78.8,2.8
13,,,00:05-00:10,102,77.2,4.8
14,,,00:10-00:15,62,81.2,2.3
15,,,00:15-00:20,79,76.9,3.3
16,,,00:20-00:25,84,77.4,3.6
17,,,00:25-00:30,69,77.2,2.7
18,,,00:30-00:35,77,79.4,3.2
19,,,00:35-00:40,82,76.6,3.2
20,,,00:40-00:45,66,81.2,2.2
21,,,00:45-00:50,73,78.9,2.9
22,,,00:50-00:55,89,78.0,3.4
23,,,00:55-01:00,75,76.6,2.8
24,03]01]15,2019N11,00:00-00:05,67,78.6,2.9
25,,,00:05-00:10,98,76.2,4.7
26,,,00:10-00:15,66,77.2,2.7
27,,,00:15-00:20,82,74.5,3.5
28,,,00:20-00:25,81,75.4,3.5
29,,,00:25-00:30,75,76.1,3.2
30,,,00:30-00:35,82,77.9,3.4
31,,,00:35-00:40,79,78.7,3.2
32,,,00:40-00:45,69,78.9,2.5
33,,,00:45-00:50,76,76.7,3.0
34,,,00:50-00:55,87,74.9,3.4
35,,,00:55-01:00,78,73.5,3.0
36,03]01]14,2019N11,00:00-00:05,71,84.3,2.6
37,,,00:05-00:10,94,83.9,4.4
38,,,00:10-00:15,70,81.3,2.6
39,,,00:15-00:20,78,84.1,2.8
40,,,00:20-00:25,81,83.0,3.2
41,,,00:25-00:30,72,84.4,2.7
42,,,00:30-00:35,83,86.1,3.1
43,,,00:35-00:40,74,86.0,2.6
44,,,00:40-00:45,74,85.0,2.6
45,,,00:45-00:50,73,84.3,2.6
46,,,00:50-00:55,90,82.6,3.1
47,,,00:55-01:00,75,82.9,2.6
dfrequired = pd.read_clipboard(sep=',')
dfrequired
CodePudding user response:
Please try this:
import pandas as pd
import numpy as np
df = pd.read_csv('file.csv')
df = df.drop('Unnamed: 0', axis=1)
DAY = df.iloc[2, 0]
ID = df.iloc[0, 2]
TIME = df.iloc[2:, 1]
result_df = pd.DataFrame()
i = 0
for n in range(2, df.shape[1], 4):
if i==0:
first_col = n
last_col = n 3
temp_df = df.iloc[:, first_col:last_col]
temp_df = temp_df.iloc[2:, :]
temp_df.insert(0, 'ID', np.nan)
temp_df.iloc[0, 0] = ID
temp_df.insert(1, 'Day', np.nan)
temp_df.iloc[0, 1] = DAY
temp_df.insert(2, 'Time', np.nan)
temp_df.iloc[:, 2] = TIME
result_df = result_df.append(temp_df)
i = 1
else:
first_col = n
last_col = n 3
temp_df = df.iloc[:, first_col:last_col]
ID = temp_df.iloc[0, 0]
temp_df = temp_df.iloc[2:, :]
temp_df.insert(0, 'ID', np.nan)
temp_df.iloc[0, 0] = ID
temp_df.insert(1, 'Day', np.nan)
temp_df.iloc[0, 1] = DAY
temp_df.insert(2, 'Time', np.nan)
temp_df.iloc[:, 2] = TIME
temp_df.columns = result_df.columns
result_df = result_df.append(temp_df)
result_df = result_df.reset_index(drop=True)
CodePudding user response:
OK, there we go. First of all, I created a random sample file that looks just like yours:
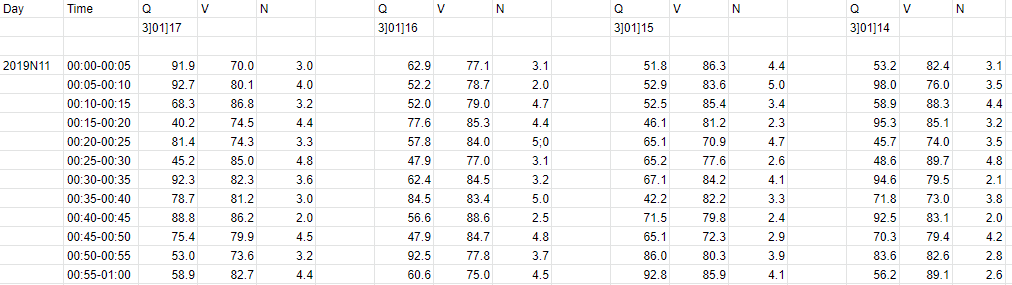
Then, I uploaded it as a dataframe:
(link here: 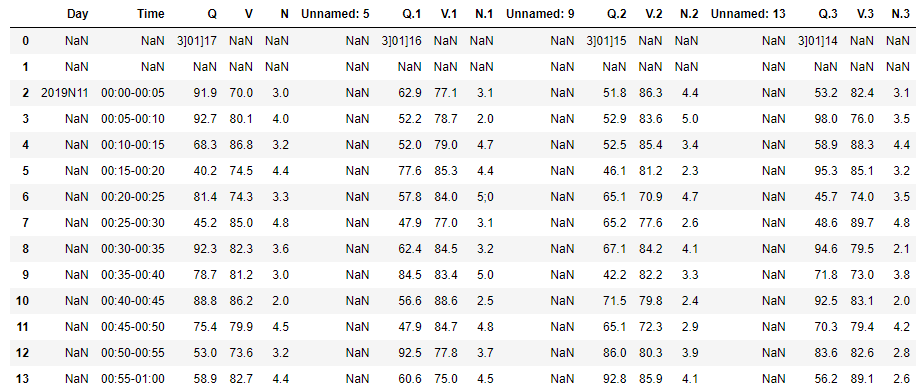
My approach was to create lists and group them as a new dataframe:
Q_index = [i for i in range(len(df.columns)) if 'Q' in df.columns[i]]
id_list = [i for sub_list in [[id] list(np.ones(11)*np.nan) for id in df.iloc[0].dropna()] for i in sub_list]
day_list = df.loc[2,'Day']
time_list = (df['Time'][2:]).tolist()*len(Q_index)
Q_list = [i for sub_list in [df.iloc[2:,i].tolist() for i in Q_index] for i in sub_list]
V_list = [i for sub_list in [df.iloc[2:,i 1].tolist() for i in Q_index] for i in sub_list]
N_list = [i for sub_list in [df.iloc[2:,i 2].tolist() for i in Q_index] for i in sub_list]
result_df = pd.DataFrame({'ID' :id_list,
'Day' :day_list,
'Time':time_list,
'Q' :Q_list,
'V' :V_list,
'N' :N_list}).fillna(method='ffill')
Output:
result_df
ID Day Time Q V N
0 3]01]17 2019N11 00:00-00:05 91.9 70.0 3.0
1 3]01]17 2019N11 00:05-00:10 92.7 80.1 4.0
2 3]01]17 2019N11 00:10-00:15 68.3 86.8 3.2
3 3]01]17 2019N11 00:15-00:20 40.2 74.5 4.4
4 3]01]17 2019N11 00:20-00:25 81.4 74.3 3.3
5 3]01]17 2019N11 00:25-00:30 45.2 85.0 4.8
6 3]01]17 2019N11 00:30-00:35 92.3 82.3 3.6
7 3]01]17 2019N11 00:35-00:40 78.7 81.2 3.0
8 3]01]17 2019N11 00:40-00:45 88.8 86.2 2.0
9 3]01]17 2019N11 00:45-00:50 75.4 79.9 4.5
10 3]01]17 2019N11 00:50-00:55 53.0 73.6 3.2
11 3]01]17 2019N11 00:55-01:00 58.9 82.7 4.4
12 3]01]16 2019N11 00:00-00:05 62.9 77.1 3.1
13 3]01]16 2019N11 00:05-00:10 52.2 78.7 2.0
14 3]01]16 2019N11 00:10-00:15 52.0 79.0 4.7
15 3]01]16 2019N11 00:15-00:20 77.6 85.3 4.4
16 3]01]16 2019N11 00:20-00:25 57.8 84.0 5;0
17 3]01]16 2019N11 00:25-00:30 47.9 77.0 3.1
18 3]01]16 2019N11 00:30-00:35 62.4 84.5 3.2
19 3]01]16 2019N11 00:35-00:40 84.5 83.4 5.0
20 3]01]16 2019N11 00:40-00:45 56.6 88.6 2.5
21 3]01]16 2019N11 00:45-00:50 47.9 84.7 4.8
22 3]01]16 2019N11 00:50-00:55 92.5 77.8 3.7
23 3]01]16 2019N11 00:55-01:00 60.6 75.0 4.5
24 3]01]15 2019N11 00:00-00:05 51.8 86.3 4.4
25 3]01]15 2019N11 00:05-00:10 52.9 83.6 5.0
26 3]01]15 2019N11 00:10-00:15 52.5 85.4 3.4
27 3]01]15 2019N11 00:15-00:20 46.1 81.2 2.3
28 3]01]15 2019N11 00:20-00:25 65.1 70.9 4.7
29 3]01]15 2019N11 00:25-00:30 65.2 77.6 2.6
30 3]01]15 2019N11 00:30-00:35 67.1 84.2 4.1
31 3]01]15 2019N11 00:35-00:40 42.2 82.2 3.3
32 3]01]15 2019N11 00:40-00:45 71.5 79.8 2.4
33 3]01]15 2019N11 00:45-00:50 65.1 72.3 2.9
34 3]01]15 2019N11 00:50-00:55 86.0 80.3 3.9
35 3]01]15 2019N11 00:55-01:00 92.8 85.9 4.1
36 3]01]14 2019N11 00:00-00:05 53.2 82.4 3.1
37 3]01]14 2019N11 00:05-00:10 98.0 76.0 3.5
38 3]01]14 2019N11 00:10-00:15 58.9 88.3 4.4
39 3]01]14 2019N11 00:15-00:20 95.3 85.1 3.2
40 3]01]14 2019N11 00:20-00:25 45.7 74.0 3.5
41 3]01]14 2019N11 00:25-00:30 48.6 89.7 4.8
42 3]01]14 2019N11 00:30-00:35 94.6 79.5 2.1
43 3]01]14 2019N11 00:35-00:40 71.8 73.0 3.8
44 3]01]14 2019N11 00:40-00:45 92.5 83.1 2.0
45 3]01]14 2019N11 00:45-00:50 70.3 79.4 4.2
46 3]01]14 2019N11 00:50-00:55 83.6 82.6 2.8
47 3]01]14 2019N11 00:55-01:00 56.2 89.1 2.6