I have a dataframe like as shown below
df = pd.DataFrame(
{'stud_name' : ['ABC', 'ABC','ABC','DEF',
'DEF','DEF'],
'qty' : [123,31,490,518,70,900],
'trans_date' : ['13/11/2020','10/1/2018','11/11/2017','27/03/2016','13/05/2010','14/07/2008']})
I would like to do the below
a) for each stud_name, look at their past data (full past data) and compute the min, max and mean of qty column
Please note that the 1st record/row for every unique stud_name will be NA because there is no past data (history) to look at and compute the aggregate statistics
I tried something like below but the output is incorrect
df['trans_date'] = pd.to_datetime(df['trans_date'])
df.sort_values(by=['stud_name','trans_date'],inplace=True)
df['past_transactions'] = df.groupby('stud_name').cumcount()
df['past_max_qty'] = df.groupby('stud_name')['qty'].expanding().max().values
df['past_min_qty'] = df.groupby('stud_name')['qty'].expanding().min().values
df['past_avg_qty'] = df.groupby('stud_name')['qty'].expanding().mean().values
I expect my output to be like as shown below
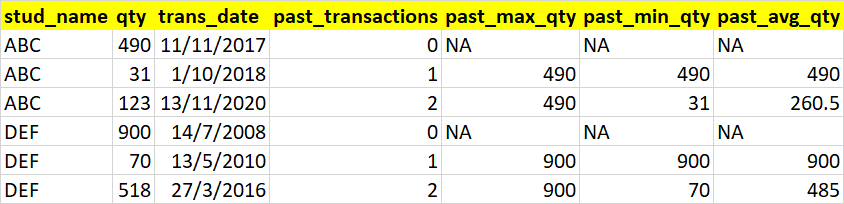
CodePudding user response:
We can use custom function to calculate the past statistics per student
def past_stats(q):
return (
q.expanding()
.agg(['max', 'min', 'mean'])
.shift().add_prefix('past_')
)
df.join(df.groupby('stud_name')['qty'].apply(past_stats))
stud_name qty trans_date past_max past_min past_mean
2 ABC 490 2017-11-11 NaN NaN NaN
1 ABC 31 2018-10-01 490.0 490.0 490.0
0 ABC 123 2020-11-13 490.0 31.0 260.5
5 DEF 900 2008-07-14 NaN NaN NaN
4 DEF 70 2010-05-13 900.0 900.0 900.0
3 DEF 518 2016-03-27 900.0 70.0 485.0