Given a dict, where keys are column labels and values are Series, I can easily build a DataFrame as such:
dat = {'col_1': pd.Series([3, 2, 1, 0], index=range(10,50,10)),
'col_2': pd.Series([4, 5, 6, 7], index=range(10,50,10))}
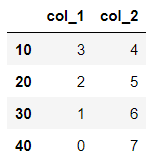
pd.DataFrame(dat)
col_1 col_2
10 3 4
20 2 5
30 1 6
40 0 7
However I have a generator that gives (key, value) tuples:
gen = ((col, srs) for col, srs in dat.items()) # generator object
Now I can trivially use the generator to create a dict and make the same Dataframe:
pd.DataFrame(dict(gen))
However this evaluates all the generator Series first, and then sends them into Pandas, and so uses twice the memory (I presume). I'd like Pandas to iterate over the generator itself as it builds the DataFrame if possible.
I can pass the generator into the DataFrame constructor, but get an odd result:
gen = ((col, srs) for col, srs in dat.items()) # generator object
pd.DataFrame(gen)
0 1
0 col_1 10 3
20 2
30 1
40 0
dtype: int64
1 col_2 10 4
20 5
30 6
40 7
dtype: int64
And I get the same result using pd.DataFrame.from_dict(gen) or pd.DataFrame.from_records(gen).
So my questions are: Can I produce my original DataFrame by passing the generator gen to Pandas? And by doing so would I reduce my memory usage (assuming a large data set, not the trivial toy example shown here).
Thanks!
CodePudding user response:
This is a partial answer. You can build your dataframe from the generator this way without the need for a conversion to a dictionary:
df = pd.DataFrame()
for x in gen:
df[x[0]] = x[1]
For the allocated memory for both methods, I tried to compare both on different notebooks or on the same notebook but after restarting and clearing the outputs each time to get true results.
First method: converting a generator to dictionary and then dataframe:
import pandas as pd
import psutil
import os
dat = {'col_1': pd.Series([3, 2, 1, 0], index=range(10,50,10)),
'col_2': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_3': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_4': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_5': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_6': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_7': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_8': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_9': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_10': pd.Series([4, 5, 6, 7], index=range(10,50,10))}
gen = ((col, srs) for col, srs in dat.items())
df = pd.DataFrame(dict(gen))
print("memory usage is {} MB".format(psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)))
#output
Memory usage is 78.55859375 MB
Second method: creating a dataframe by only iterating through the generator:
import pandas as pd
import psutil
import os
dat = {'col_1': pd.Series([3, 2, 1, 0], index=range(10,50,10)),
'col_2': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_3': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_4': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_5': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_6': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_7': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_8': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_9': pd.Series([4, 5, 6, 7], index=range(10,50,10)),
'col_10': pd.Series([4, 5, 6, 7], index=range(10,50,10))}
gen = ((col, srs) for col, srs in dat.items())
df = pd.DataFrame()
for x in gen:
df[x[0]] = x[1]
print("Memory usage is {} MB".format(psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)))
#output
Memory usage is 78.69921875 MB
Conclusion, there is very small difference in terms of memory, but converting a generator to a dictionary more efficient in terms of time.
CodePudding user response:
You can simply convert the generator to a dict and then create a dataframe from it:
# Create generator
dat = {'col_1': pd.Series([3, 2, 11, 0], index=range(10,50,10)),
'col_2': pd.Series([4, 5, 6, 7], index=range(10,50,10))}
gen = ((col, srs) for col, srs in dat.items())
# Create df
pd.DataFrame.from_dict(dict(gen))
Output:
col_1 col_2
10 3 4
20 2 5
30 11 6
40 0 7