I have 2 dataframes like as shown below
df = pd.DataFrame(
{'stud_name' : ['ABC', 'ABC','ABC','ABC',
'DEF'],
'ques_date' : ['13/11/2020', '10/1/2018','11/11/2017', '27/03/2016',
'13/05/2010']})
df_score = pd.DataFrame(
{'stud_name' : ['ABC', 'ABC','ABC','ABC','ABC','ABC','ABC','DEF','DEF','DEF','DEF'],
'qtr':['Q1','Q2','Q3','Q4','Q1','Q2','Q3','Q3','Q4','Q2','Q4'],
'year' : [2015,2015,2015,2015,2016,2017,2017,2017,2017,2018,2017],
't_score':[11,13,15,17,12,312,14,15,18,43,32],
'p_score':[32,45,32,21,56,87,32,786,213,32,11]})
I would like to do the below
a) For each stud_name, compute two moving average (of t_score) columns as output
mov_avg_full = use all past data of a stud_name. (all past quarters info from df_score)
mov_avg_2qtr = use data from past 2 quarters (only past 2 quarters info from df_score)
ex: if the year is 2020 and it is 3rd qtr, I would like to compute moving average of all past data (before 2020 Q3) and moving average of last 2 quarters (2020 Q1 and 2020 Q2)
If there is no past data for a specific stud_name, we just put NA (ex: DEF has no past data in df_score)
I tried the below
df['ques_date'] = pd.to_datetime(df['ques_date'], dayfirst=True)
df.sort_values(by=['stud_name','ques_date'],inplace=True)
df['act_qtr'] = df['ques_date'].dt.to_period('Q').dt.strftime('Q%q')
df['year'] = df['ques_date'].dt.year
df_score.sort_values(by=['year','qtr'],inplace=True)
df_full = df.merge(df_score,on=['stud_name'])
df_full['mov_avg_2qtr'] = df_full['t_score'].rolling(2).mean() # this is incorrect
I expect my output to be like as shown below
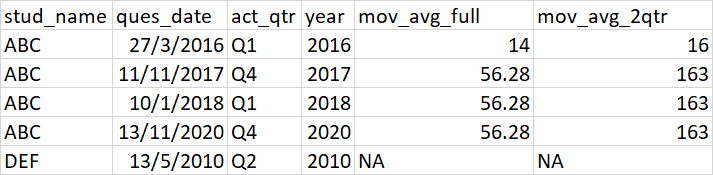
CodePudding user response:
You might want to use rolling and expanding methods. After obtaining the Cartesian product of quarterly indice, you can apply a date mask to get the target rows.
Code:
import pandas as pd
# Create sample dataframes
df = pd.DataFrame({'stud_name': ['ABC', 'ABC','ABC','ABC', 'DEF'], 'ques_date' : ['13/11/2020', '10/1/2018','11/11/2017', '27/03/2016', '13/05/2010']})
df_score = pd.DataFrame({'stud_name': ['ABC', 'ABC','ABC','ABC','ABC','ABC','ABC','DEF','DEF','DEF','DEF'], 'qtr':['Q1','Q2','Q3','Q4','Q1','Q2','Q3','Q3','Q4','Q2','Q4'], 'year' : [2015,2015,2015,2015,2016,2017,2017,2017,2017,2018,2017], 't_score':[11,13,15,17,12,312,14,15,18,43,32], 'p_score':[32,45,32,21,56,87,32,786,213,32,11]})
# Assign necessary datetime objects
df['ques_date'] = pd.to_datetime(df.ques_date, format='%d/%m/%Y')
df[['act_qtr', 'act_year', 'act_key']] = df['ques_date'].map(lambda e: [f'Q{e.quarter}', e.year, e.to_period('Q')]).apply(pd.Series)
df_score['key'] = df_score.year.astype(str) df_score.qtr
# Calculate the two kinds of the moving average
df_score.sort_values(['year', 'qtr'], inplace=True)
df_score['mov_avg_full'] = df_score.groupby('stud_name')['t_score'].expanding().mean().values
df_score['mov_avg_2qtr'] = df_score.groupby('stud_name')['t_score'].rolling(2).mean().values
# Get a cross-joined dataframe
df_full = df.merge(df_score, on='stud_name').sort_values(['act_key', 'key'])
# Apply a datetime mask
df_full = df_full[df_full.key < df_full.act_key].groupby(['stud_name', 'act_qtr', 'act_year'], as_index=False).last()
# Deal with the missing null values and use necessary columns
df_full = df.merge(df_full, how='left', on=['stud_name', 'ques_date', 'act_qtr', 'act_year'])
df_full = df_full[['stud_name', 'ques_date', 'act_qtr', 'act_year', 'mov_avg_full', 'mov_avg_2qtr']]
print(df_full)
Output:
| stud_name | ques_date | act_qtr | act_year | mov_avg_full | mov_avg_2qtr |
|---|---|---|---|---|---|
| ABC | 2020-11-13 00:00:00 | Q4 | 2020 | 56.2857 | 163 |
| ABC | 2018-01-10 00:00:00 | Q1 | 2018 | 56.2857 | 163 |
| ABC | 2017-11-11 00:00:00 | Q4 | 2017 | 56.2857 | 163 |
| ABC | 2016-03-27 00:00:00 | Q1 | 2016 | 14 | 16 |
| DEF | 2010-05-13 00:00:00 | Q2 | 2010 | nan | nan |