This is my output: I want to remove these from my output '4.9 out of 5 stars', '1,795 ratings',
'4.9 out of 5 stars', '1,795 ratings', '#3,626 in Kitchen & Dining (', 'See Top 100 in Kitchen & Dining', ')', '#18 in', 'Measuring Spoons'
This is my page link 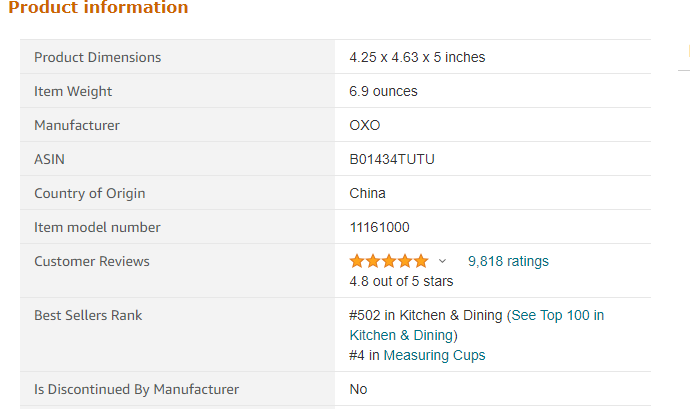
This is my code:
from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'pushpa'
start_urls = ['https://www.amazon.com/s?k=measuring tools & scales&crid=10FYGF4D5KRO0&sprefix=measuring tools and scal,aps,363&ref=nb_sb_ss_ts-doa-p_4_24']
custom_settings = {
'CONCURRENT_REQUESTS_PER_DOMAIN': 1,
'DOWNLOAD_DELAY': 1,
'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
def parse(self, response):
books = response.xpath("//div//h2//@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
coordinate = response.xpath("//table[@id='productDetails_detailBullets_sections1']//td//span//text()")[2:].extract()
coordinate = [i.strip() for i in coordinate]
# remove empty strings:s
coordinate = [i for i in coordinate if i]
yield{
'Best_sellerrank':coordinate
}
CodePudding user response:
Your xpath is correct and you can get your desired output just using list slicing and split method.
from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'pushpa'
start_urls = ['https://www.amazon.com/s?k=measuring tools & scales&crid=10FYGF4D5KRO0&sprefix=measuring tools and scal,aps,363&ref=nb_sb_ss_ts-doa-p_4_24']
custom_settings = {
'CONCURRENT_REQUESTS_PER_DOMAIN': 1,
'DOWNLOAD_DELAY': 1,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
def parse(self, response):
books = response.xpath("//div//h2//@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
coordinate = response.xpath("//table[@id='productDetails_detailBullets_sections1']//td//span//text()")[2:].extract()
coordinate = [i.strip() for i in coordinate]
# remove empty strings:s
coordinate = [i for i in coordinate if i]
coordinate = coordinate[:2]
coordinate = ', '.join([i for i in coordinate])
yield{
'Best_sellerrank':coordinate
}
Output:
{'Best_sellerrank': '4.7 out of 5 stars, 43,078 ratings'}
... so on