I have a text file that looks like below.
Name : ValueA
Age: 23
Height: 178cm
Name : ValueB
Age: 22
Height: 168cm
Weight: 80Kg
Name : ValueC
Age: 40
Height: 188cm
IQ: 150
I am looking for code to iterate through the and create a csv with text starting with Name as first column, and other properties as other columns.
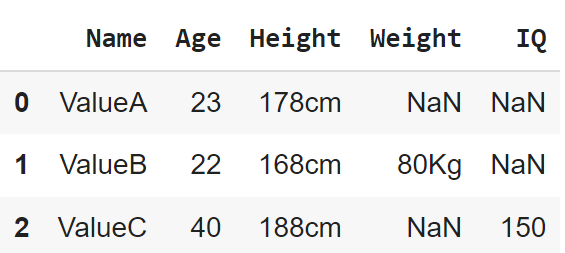
It should look something like below:
| Name | Age | Height | Weight | IQ |
|---|---|---|---|---|
| ValueA | 23 | 178cm | NA | NA |
| ValueB | 22 | 168cm | 80kg | NA |
| ValueC | 40 | 188cm | NA | 150 |
All Names have unique values
CodePudding user response:
You can use the below parsing:
import pandas as pd
# assuming your file is called "test.txt"
with open("test.txt", "r") as f:
t = [line.strip() for line in f.readlines()]
# Organise data
stuff = {}
index = 0
for line in t:
key, value = line.split(": ")
if "Name" in key:
stuff[index] = {"Name": value}
current_key = index
index = 1
else:
stuff[current_key][key] = value
# create dataframe
result_df = pd.DataFrame(stuff).T
# Create CSV
# you can remove the numerical index if not useful in the CSV by using "index=False"
result_df.to_csv("test.csv")
OUTPUT: