I'm trying to load a specific file from group of file.
example : I have files in hdfs in this format app_name_date.csv, i have 100's of files like this in a directory. i want to load a csv file into dataframe based on date.
dataframe1 = spark.read.csv("hdfs://XXXXX/app/app_name_ $currentdate .csv") but its throwing error since $currentdate is not accepting and says file doesnot exists
error : pyspark.sql.utils.AnalysisException: Path does not exist: hdfs://XXXXX/app/app_name_ $currentdate .csv"
any idea how to do this in pyspark
CodePudding user response:
You can format the string with:
from datetime import date
formatted = date.today().strftime("%d/%m/%Y")
f"hdfs://XXXXX/app/app_name_{formatted}.csv"
Out[25]: 'hdfs://XXXXX/app/app_name_02/03/2022.csv'
CodePudding user response:
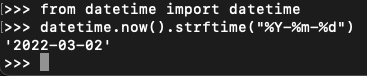
use this option from datetime package