I'm trying to learn Painless so that I could use it while trying to enrich and manipulate incoming documents. However, every way I've seen for accessing the document just results in errors. Having input this in the Painless Lab in Kibana, these are the errors I'm getting:
def paths = new String[3];
paths[0]= '.com';
paths[1] = 'bar.com';
paths[2] = 'foo.bar.com';
doc['my_field'] = paths; // does not work: '[Ljava.lang.String; cannot be cast to org.elasticsearch.index.fielddata.ScriptDocValues'
ctx.my_field = paths; // does not compile: 'cannot resolve symbol [ctx.my_field]'
return doc['my_field'] == 'field_value'; // does not work: 'No field found for [my_field] in mapping'
doc['my_field'] == 'field_value' complains despite the field being present in the test document, though doc.containsKey('my_field') does return false.
How should I actually be accessing and manipulating the incoming document? I'm using ElasticSearch 7.12.
CodePudding user response:
You can create 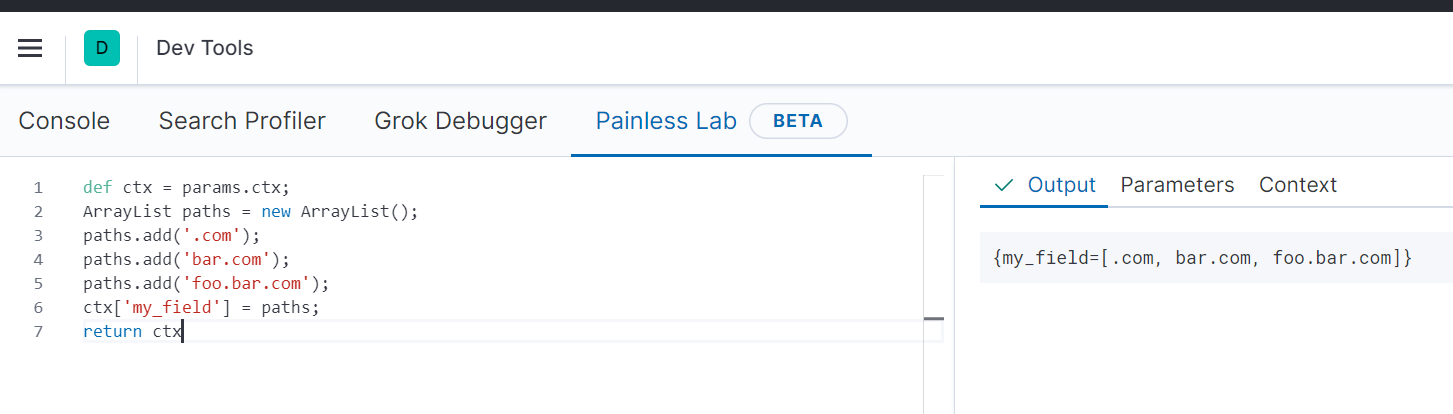
Add below in parameters tab, i missed to add this in answer. this required because in actual implmentation you will get value from context and update context.
{
"ctx":{
"my_field":["test"]
}
}