I'm attempting to create a std::vector<std::set<int>> with one set for each NUMA-node, containing the thread-ids obtained using omp_get_thread_num().
Topo:
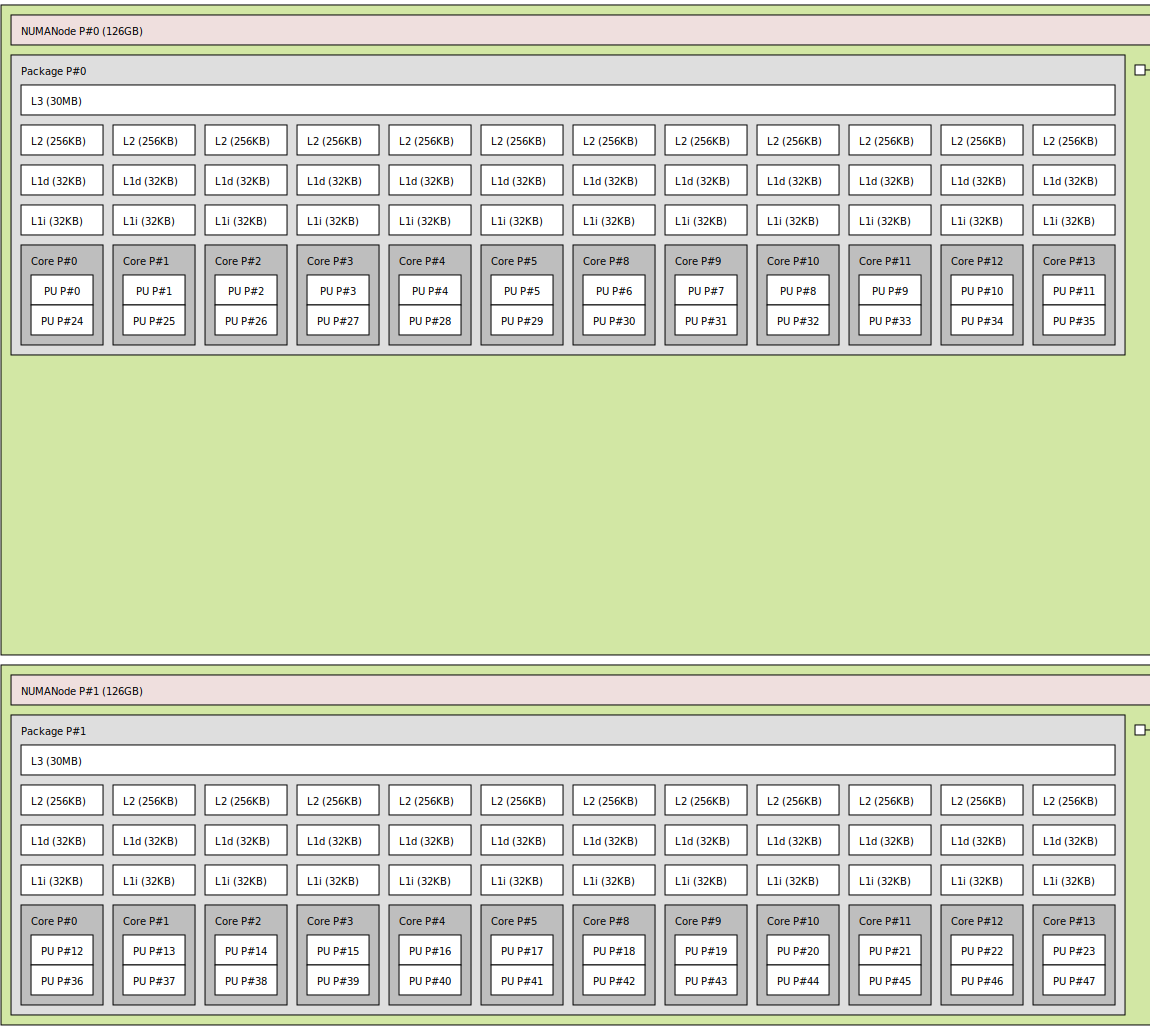
Idea:
- Create data which is larger than L3 cache,
- set first touch using thread 0,
- perform multiple experiments to determine the minimum access time of each thread,
- extract the threads into nodes based on sorted access times and information about the topology.
Code: (Intel compiler, OpenMP)
// create data which will be shared by multiple threads
const auto part_size = std::size_t{50 * 1024 * 1024 / sizeof(double)}; // 50 MB
const auto size = 2 * part_size;
auto container = std::unique_ptr<double>(new double[size]);
// open a parallel section
auto thread_count = 0;
auto thread_id_min_duration = std::multimap<double, int>{};
#ifdef DECIDE_THREAD_COUNT
#pragma omp parallel num_threads(std::thread::hardware_concurrency())
#else
#pragma omp parallel
#endif
{
// perform first touch using thread 0
const auto thread_id = omp_get_thread_num();
if (thread_id == 0)
{
thread_count = omp_get_num_threads();
for (auto index = std::size_t{}; index < size; index)
{
container.get()[index] = static_cast<double>(std::rand() % 10 1);
}
}
#pragma omp barrier
// access the data using all threads individually
#pragma omp for schedule(static, 1)
for (auto thread_counter = std::size_t{}; thread_counter < thread_count; thread_counter)
{
// calculate the minimum access time of this thread
auto this_thread_min_duration = std::numeric_limits<double>::max();
for (auto experiment_counter = std::size_t{}; experiment_counter < 250; experiment_counter)
{
const auto* data = experiment_counter % 2 == 0 ? container.get() : container.get() part_size;
const auto start_timestamp = omp_get_wtime();
for (auto index = std::size_t{}; index < part_size; index)
{
static volatile auto exceedingly_interesting_value_wink_wink = data[index];
}
const auto end_timestamp = omp_get_wtime();
const auto duration = end_timestamp - start_timestamp;
if (duration < this_thread_min_duration)
{
this_thread_min_duration = duration;
}
}
#pragma omp critical
{
thread_id_min_duration.insert(std::make_pair(this_thread_min_duration, thread_id));
}
}
} // #pragma omp parallel
Not shown here is code which outputs the minimum access times sorted into the multimap.
Env. and Output
- How do
OMP_PLACESandOMP_PROC_BINDwork?
I am attempting to not use SMT by using export OMP_PLACES=cores OMP_PROC_BIND=spread OMP_NUM_THREADS=24. However, I'm getting this output:
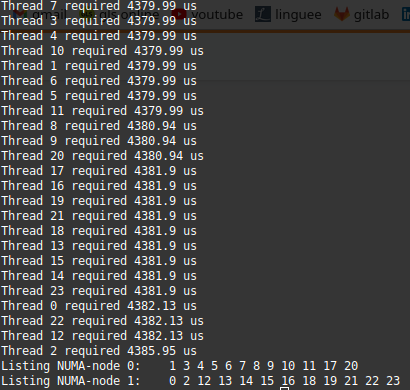
What's puzzling me is that I'm having the same access times on all threads. Since I'm trying to spread them across the 2 NUMA nodes, I expect to neatly see 12 threads with access time, say, x and another 12 with access time ~2x.
- Why is the above happening?
Additional Information
Even more puzzling are the following environments and their outputs:
export OMP_PLACES=cores OMP_PROC_BIND=spread OMP_NUM_THREADS=26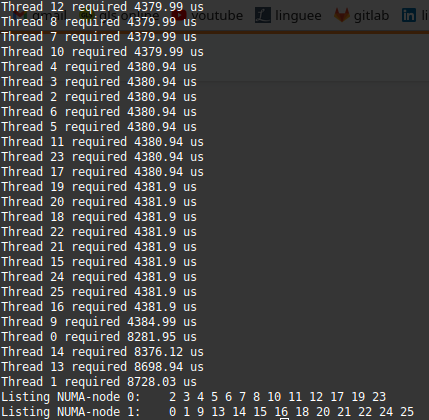
export OMP_PLACES=cores OMP_PROC_BIND=spread OMP_NUM_THREADS=48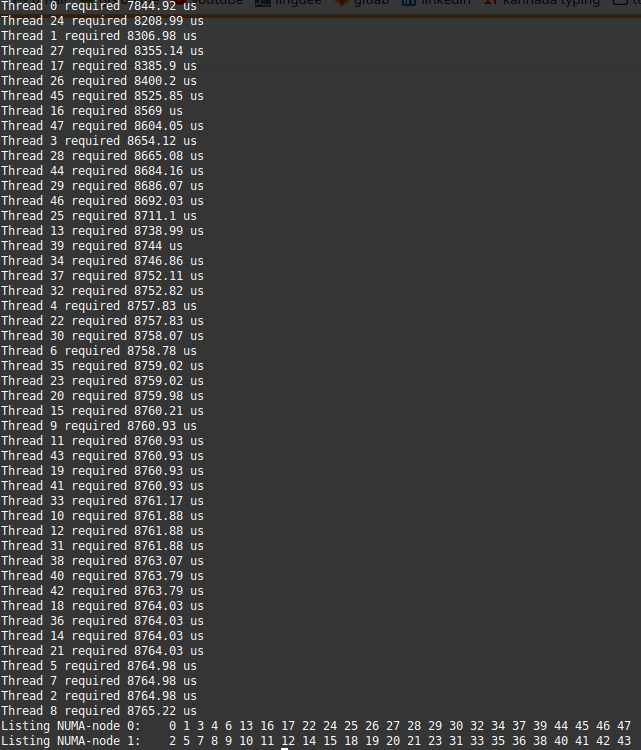
Any help in understanding this phenomenon would be much appreciated.
CodePudding user response:
Put it shortly, the benchmark is flawed.
perform multiple experiments to determine the minimum access time of each thread
The term "minimum access time" is unclear here. I assume you mean "latency". The thing is your benchmark does not measure the latency. volatile tell to the compiler to read store data from the memory hierarchy. The processor is free to store the value in its cache and x86-64 processors actually do that (like almost all modern processors).
How do OMP_PLACES and OMP_PROC_BIND work?
You can find the documentation of both here and there. Put it shortly, I strongly advise you to set OMP_PROC_BIND=TRUE and OMP_PLACES="{0},{1},{2},..." based on the values retrieved from hw-loc. More specifically, you can get this from hwloc-calc which is a really great tool (consider using --li --po, and PU, not CORE because this is what OpenMP runtimes expect). For example you can query the PU identifiers of a given NUMA node. Note that some machines have very weird non-linear OS PU numbering and OpenMP runtimes sometimes fail to map the threads correctly. IOMP (OpenMP runtime of ICC) should use hw-loc internally but I found some bugs in the past related to that. To check the mapping is correct, I advise you to use hwloc-ps. Note that OMP_PLACES=cores does not guarantee that threads are not migrating from one core to another (even one on a different NUMA node) except if OMP_PROC_BIND=TRUE is set (or a similar setting). Note that you can also use numactl so to control the NUMA policies of your process. For example, you can tell to the OS not to use a given NUMA node or to interleave the allocations. The first touch policy is not the only one and may not be the default one on all platforms (on some Linux platforms, the OS can move the pages between the NUMA nodes so to improve locality).
Why is the above happening?
The code takes 4.38 ms to read 50 MiB in memory in each threads. This means 1200 MiB read from the node 0 assuming the first touch policy is applied. Thus the throughout should be about 267 GiB/s. While this seems fine at first glance, this is a pretty big throughput for such a processor especially assuming only 1 NUMA node is used. This is certainly because part of the fetches are done from the L3 cache and not the RAM. Indeed, the cache can partially hold a part of the array and certainly does resulting in faster fetches thanks to the cache associativity and good cache policy. This is especially true as the cache lines are not invalidated since the array is only read. I advise you to use a significantly bigger array to prevent this complex effect happening.
You certainly expect one NUMA node to have a smaller throughput due to remote NUMA memory access. This is not always true in practice. In fact, this is often wrong on modern 2-socket systems since the socket interconnect is often not a limiting factor (this is the main source of throughput slowdown on NUMA systems).
NUMA effect arise on modern platform because of unbalanced NUMA memory node saturation and non-uniform latency. The former is not a problem in your application since all the PUs use the same NUMA memory node. The later is not a problem either because of the linear memory access pattern, CPU caches and hardware prefetchers : the latency should be completely hidden.
Even more puzzling are the following environments and their outputs
Using 26 threads on a 24 core machine means that 4 threads have to be executed on two cores. The thing is hyper-threading should not help much in such a case. As a result, multiple threads sharing the same core will be slowed down. Because IOMP certainly pin thread to cores and the unbalanced workload, 4 threads will be about twice slower.
Having 48 threads cause all the threads to be slower because of a twice bigger workload.
CodePudding user response:
Let me address your first sentence. A C std::vector is different from a C malloc. Malloc'ed space is not "instantiated": only when you touch the memory does the physical-to-logical address mapping get established. This is known as "first touch". And that is why in C-OpenMP you initialize an array in parallel, so that the socket touching the part of the array gets the pages of that part. In C , the "array" in a vector is created by a single thread, so the pages wind up on the socket of that thread.
Here's a solution:
template<typename T>
struct uninitialized {
uninitialized() {};
T val;
constexpr operator T() const {return val;};
double operator=( const T&& v ) { val = v; return val; };
};
Now you can create a vector<uninitialized<double>> and the array memory is not touched until you explicitly initialize it:
vector<uninitialized<double>> x(N),y(N);
#pragma omp parallel for
for (int i=0; i<N; i )
y[i] = x[i] = 0.;
x[0] = 0; x[N-1] = 1.;
Now, I'm not sure how this goes if you have a vector of sets. Just thought I'd point out the issue.