I am trying to create equal part files while writing the dataframe in Pyspark. Each part file needs to be 100Mb. Is there a way to do it?
Currently, I write the dataframe in a location called path. Get the total size from path. After getting the total size divide by 100 and then df.coalesce(file_number).write.csv(another_path). When I do this I am getting equal parts but not 100MB. Can someone help with this?
CodePudding user response:
It is impossible to control the creation of equally sized files.
The number of files that gets written is controlled by the parallelization of DataFrame or RDD.
However, since Spark 2.2 you can control the number maxRecordsPerFile option when you write data. With this you can limit the number of records that get written per file in each partition. The other option of course would be to repartition.
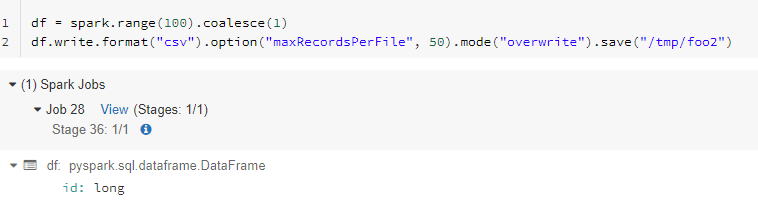
Output Directory

Additionally, if you use delta lake though the output files would be in parquet format. Even if the partition are not evenly distributed in that case you just have to run ZOrder By (depending on your frequency of execution) as below -
OPTIMIZE events
ZORDER BY (eventType)
Z-Ordering aims to produce evenly-balanced data files with respect to the number of tuples, but not necessarily data size on disk.
See this Databricks documentation link on the same for more details - https://docs.databricks.com/delta/optimizations/file-mgmt.html
CodePudding user response:
It's depending on your dataset size.
The output size (Check using spark UI) - by understanding what is the size, you will get the sense of how many partitions you should coalesce, there is no magic argument.
The only thing that may help your is maybe using also
"spark.sql.files.maxPartitionBytes": "134217728"
This will ensure that the maximum size will be 128mb (its in bytes)